

GreenSQL: un reverse proxy contro gli attacchi SQL injection
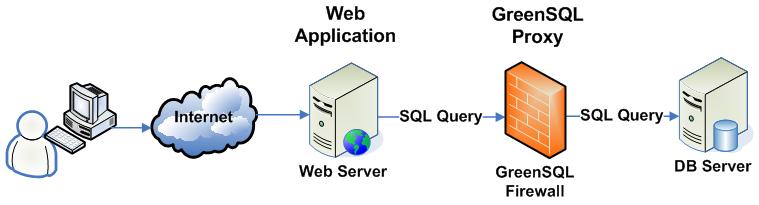
GreenSQL è un’interessante applicazione che promette di proteggere un database da eventuali attacchi dannosi. Sostanzialmente si tratta di un firewall open source che fa da filtro tra l’applicazione web e il database. Funziona come un proxy, l’applicazione invece di connettersi al database si connette a GreenSQL che poi gestisce la connessione con il database vero e proprio.
Attacchi SQL injection
Un attacco di tipo SQL injection consiste nell’inserimento “injection” di una particolare query SQL nei dati passati in input ad una applicazione da parte di un client allo scopo di provocare l’esecuzione di comandi SQL predefiniti.
Un exploit di tipo SQL injection se coronato da successo può rivelare dati sensibili da un database, modificarli, eseguire operazioni amministrative sul database (come uno shutdown od un backup), e talvolta anche impartire comandi al sistema operativo sottostante.
GreenSQL è un database firewall Open Source utilizzabile per proteggere le basi di dati da attacchi di tipo SQL injection, operando come un proxy per comandi SQL,e con integrato il supporto per Mysql.
La sua logica operativa si basa sulla valutazione dei comandi SQL, sia utilizzando una matrice di indici di rischio, sia bloccando comandi amministrativi del db (DROP, CREATE, etc).
GreenSQL opera come un reverse proxy per le connessioni Mysql. Vale a dire che invece del server Mysql, le applicazioni si connettono al server GreenSQL, che analizzerà le queries SQL e le inoltrerà al server Mysql di back-end.
Sostanzialmente funziona così: se la query mandata dall’applicazione è ritenuta rischiosa da parte di GreeSQL essa non viene mandata al DB e GreenSQL restituisce all’applicazione un risultato nullo. Alternativamente, se la query non presenta problemi, viene inviata al server e la rispostata arriva poi alla web application.
Per default GreenSQL lavora sulla porta 3305 girando tutte le richieste al server Mysql sulla porta
http://127.0.0.1:3306
Si puo’ configurare in modalita’ differenti quali :
- Simulation Mode (database IDS): Non effettua nessuna operazione ma permette l’analisi del comportamento di GreenSQL.
- Blocking Suspicious Commands (database IPS): In questa modalita’ effettua un analisi euristica per cercare query giudicate “illegali” e le blocca automaticamente. In questa modalita’ si richia di bloccare falsi positivi e far eseguire query che risultano essere falsi negativi.
- Learning mode: si usa per evitare i problemi del Blocking Suspicious mode. Permette di visionare l’analisi della query e “informare” di volta in volta il software se bloccare o no questo tipo di operazioni.
- Active protection from unknown queries (db firewall): dopo un certo periodo di “apprendimento” nella modalita’ learning mode il sistema puo’ passare alla fase successiva (bene, ho imparato tutto, ora sono pronto ad operare da solo!).
Passiamo ora all’installazione:
Si scarichi l’ultima versione del software dalla url del sito http://www.greensql.net in particolare la “GreenSQL Firewall”
riferito alla vostra piattaforma ed una volta installato il pacchetto inerente alla vostra piattaforma.
Dopo l’installazione il server greensql girera’ sulla porta 3305. provate ad accedervi con il comando:
mysql -h 127.0.0.1 -P 3305 -u root -p
Dopo aver digitato la password di root dovreste andare sul prompt di mysql (quit per uscire).
Ora il sistema e’ pronto per essere utilizzato. Non dovete far altro che avere l’accortezza di modificare i vostri script di configurazione chiedendo di connettersi sulla porta 3305 piuttosto che la 3306.
Se ad esempio il vostro CMS e’ gia’ impostato per effettuare la connessione sulla porta di default allora editate il configuration.php (o relativo file) nella sezione specifica. Ad esempio se trovate qualcosa del tipo:
$link = mysql_connect('localhost', 'mysql_user', 'mysql_password');
sostituitela con
$link = mysql_connect('localhost:3305', 'mysql_user', 'mysql_password');
Installiamo ora la greensql-console che permette di gestire, manutenere ed impostare tutte le caratteristiche di GreenSQL.
Scaricate sempre dal link per i download scaricate la “Management Console” relativa alla vostra piattaforma :
tar xvfz greensql-console-<VERSIONE> -C /opt/ cd /opt/greensql-console vim config.php
Editate i campi:
$db_name = "greendb"; $db_user = "green"; $db_pass = "greensqlpassword";
Accertatevi di aver impostato i permessi della cartella template_c a 777:
# chmod 777 templates_c
Ora potete accedere via web alla management Console dalla URL:
http://<vostro_indirizzo_ip>/greensql-console
Da qui potete verificare tutte le operazioni che effettua il GreenSQL con le varie possibilita’ di operare.
Infine per fermare e riavviare il servizio potete eseguire i comandi:
/etc/init.d/greensql-fw stop /etc/init.d/greensql-fw start
Buon divertimento !



