OK, con questa dichiarazione si capirà che sono un sistemista di vecchia scuola, per l’appunto ho iniziato ad occuparmi di sistemi HPC/Cluster nei primi anni 2000 ed ho realizzato il mio primo importante sistema Cluste HPC nel lontano 2004, da quel momento ho lavorato nello stesso ambito per grosse aziende in ambiti bancario, assicurativo, editoria, pubblica amministrazione etc…… ; ho potuto dunque analizzare per esperienza diretta che quello che legava tutti questi ambienti, che si stavano aprendo al mondo dell’offerta di servizi web online per i loro clienti (outsourcing), era la “ovvia” gestione in loco (on premise) dei dati aziendali, nonostante questo comportasse un forte investimento in hardware/network e sviluppo del software. Tutto ciò permetteva di tenere sotto controllo l’andamento dei progetti perchè per far funzionare tutti quegli avanzamenti tecnologici serviva far crescere anche il livello di preparazione tecnologica del proprio personale IT, seppur con le dovute integrazioni esterne di consulenti ad hoc, atti a portare uno slancio alla realizzazione finale del prodotto.
Dunque in un’azienda servivano un tot persone skillate in vari ambiti che procedessero di pari passo nel far avanzare il progetto fungendo anche da beta tester per i colleghi degli altri team, team solitamente suddivisi in:
- Sistemisti
- Database Administrator
- Networking
- Sviluppo (developer)
- Cyber Security
Ogni gruppo testava se stesso e faceva da tester per gli altri così da arrivare , step by step, ai vari rilasci di pre-produzione e produzione, diminuendo, a mio avviso, di gran lunga il Bug da errore umano.
Credo che tutto ciò abbia funzionato piuttosto bene, in una specie di “status quo” fino all’arrivo della crisi del 2008 ed in particolare degli strascichi sui budget i cui effetti si sono visti negli anni subito successivi, nel frattempo il maggior sviluppo di piattaforme Cloud proposte dai Big come Gloogle Cloud ed Amazon AWS (in particolare) hanno portato alla decisione sempre più massiccia dei Manager di esternalizzare tutti i processi verso queste piattaforme per massimizzare gli sforzi nello sviluppo (programmazione) dei servizi eliminando dai budget le spese hardware, quelle per le location da dedicare alla ridondanza dei dati ed ai sistemi di backup integrati. Tutto questo ora era possibile pagarlo in un forfait di servizi on chain offerti dalle piattaforme Web-Cloud che hanno invaso il campo di gioco con acronimi di ogni genere, tra cui i primi furono le PaaS, SaaS, IaaS, CaaS, DaaS etc…. (solo la fantasia li può fermare) tagliando così anche le competenze dirette dei team poichè adesso le piattaforme web, la loro gestione, il mantenimento software, gli aggiornamenti, i backup, le problematiche di rete, i DNS, le connessioni VPN, la sicurezza e quant’altro potevano essere preoccupazione ed appannaggio di altri.
Tutto ciò per me ha solo impoverito il nucleo di esperti IT, smembrando i suddetti team e generando nuovi mostri poichè le aziende diventarono prede di “metodologie” di lavoro in stile Silicon Valley (ma ehi la verità è che funzionano solo in Silicon Valley) come la Agile, è da li sono partiti inglesismi lavorativi come lo “stand up meeting”, il “parking lot”, arrivando oggi all’uso di Framework per supportare l’Agile come lo “Scrum” che ha introdotto la figura dello “scrum master” e via di questo passo.
Ma quello che si è potuto vedere è che mentre prima i Team IT aziendali necessitavano di specifiche competenze , adesso posson bastare come capo progetto uno sviluppatore Senior con conoscenze da sistemista o un sistemista con conoscenze di programmazione per mandare avantiil 70% dei progetti perchè il resto lo prepara la piattaforma Cloud che ti aiuta a gestirlo con comodi tool grafici Plug ‘n Play e se qualcosa non funziona c’è il blog/tutorial o il call center…….. semplice giusto?
Certo qualcuno potrà giustamente dire che così è tutto più mirato, perchè no più comodo, e le aziende possono essere più verticali sullo sviluppo e sul risultato finale, FORSE, ma se devo cedere capacità cognitive, conoscenza dei sistemi e competenze di problem solving solo perchè è più pratico allora forse sto sbagliando mestiere. Non parliamo poi del nuovo arrivato, la A.I. , con ChatGPT e compagnia bella… quella unita ai movimenti No-Code, non fanno ben sperare per una futura esistenza delle ultime figure rimaste (gli sviluppatori) che credo si dovranno preparare a periodi di transizione poco rosei.
Il futuro non lo si può arrestare, arriva comunque dunque è giusto imparare a conoscerlo per capire come e quali cose sono vantaggiose da utilizzare, e che cosa invece determinerà la perdita di competenze apprese con fatica, studio ed esperienza lavorativa. Si potrebbe fare qualcosa per riprendere un minimo il controllo? Credo di SI, innanzitutto diminuendo la dipendenza dai sistemi Cloud esterni e tornando a volersi sporcare le mani in casa, quindi spazio alla rinascita dei data center aziendali costruiti su misura dei progetti reali ed implementati dalle persone che li gestiranno e li faranno crescere e scalare nel tempo, quindi riprendiamoci il controllo dei dati, in primis, e dei sistemi con loro, più sistemi on premise e Edge Computing e meno esternalizzazione con il Cloud Computing.
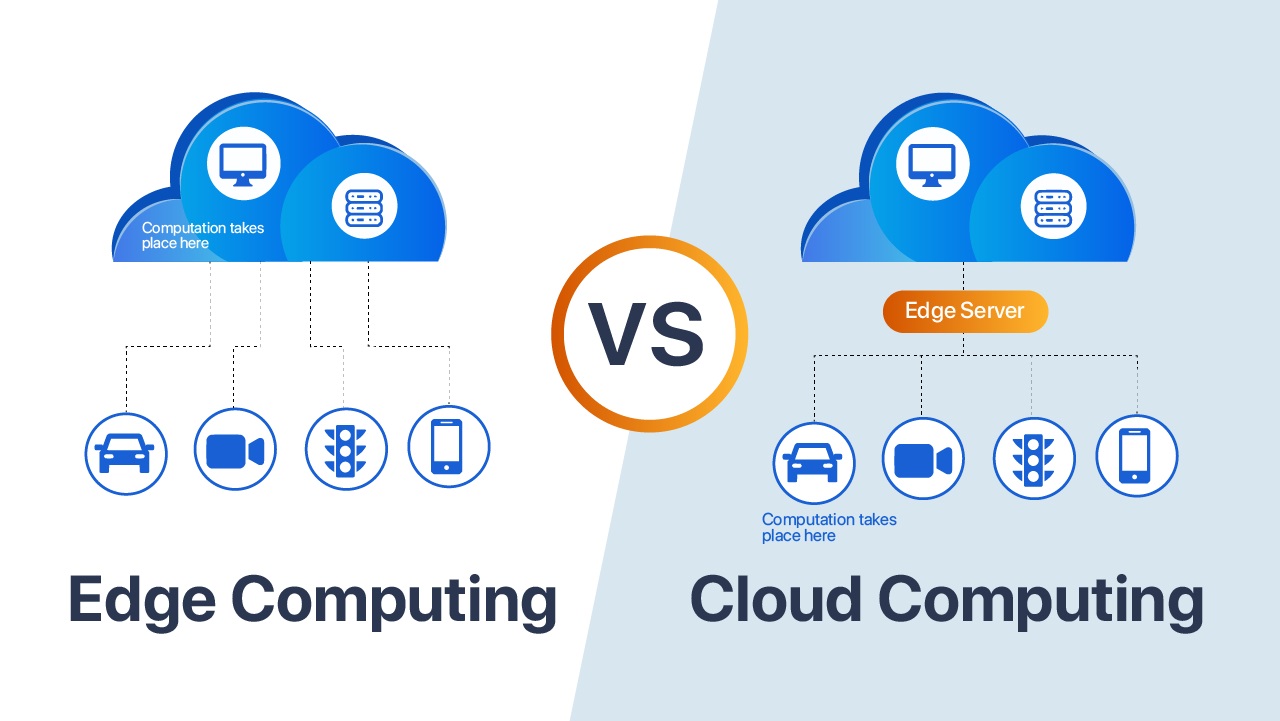
Vantaggi dell’ Edge Computing
L’edge computing è preferibile al cloud computing in molte situazioni e per diversi motivi chiave, tra cui sicurezza, controllo dei dati e velocità di elaborazione dei dati.
- Sicurezza: Nell’edge computing, i dati sono elaborati più vicino alla loro origine, riducendo il rischio di esposizione a minacce esterne. Questo approccio migliora la sicurezza dei dati sensibili.
- Controllo dei Dati: Con l’edge computing, le organizzazioni mantengono un maggiore controllo sui propri dati. I dati rimangono locali o in prossimità dei dispositivi, consentendo un controllo diretto sull’accesso e sulla gestione.
- Velocità nell’Elaborazione dei Dati: Poiché i dati vengono elaborati localmente nell’edge computing, la latenza è ridotta al minimo. Questo è fondamentale per applicazioni in tempo reale, come il monitoraggio industriale o i molti sistemi di monitoraggio delle città moderne (IoT), dove ogni millisecondo conta.
- Risparmio di Banda: Elaborare i dati in loco riduce la necessità di trasferire grandi quantità di dati in cloud, risparmiando banda e costi associati.
- Affidabilità: L’edge computing migliora l’affidabilità delle applicazioni. In caso di interruzione della connettività cloud, i dispositivi edge possono continuare a funzionare autonomamente.
- Scalabilità: L’edge computing è altamente scalabile. È possibile aggiungere dispositivi edge in modo modulare per gestire carichi di lavoro crescenti.
- Privacy: Per alcune applicazioni, come il monitoraggio della salute in tempo reale, la privacy dei dati è essenziale. L’edge computing mantiene i dati locali, riducendo le preoccupazioni sulla privacy.
In sintesi, l’edge computing è una soluzione vantaggiosa per applicazioni che richiedono velocità, sicurezza e controllo dei dati. Tuttavia, è importante notare che non esclude completamente il cloud computing, ma piuttosto lo integra in un modello ibrido per massimizzare i benefici.
Svantaggi dell’uso del Cloud Computing
- Aumento della Latenza: Nel Cloud, i dati devono viaggiare attraverso una rete molto estesa fino ai server remoti, causando ritardi (latenza) nell’elaborazione. Nel modello di Edge Computing, la distribuzione delle risorse di elaborazione avviene all’edge della rete, vicino ai dispositivi o ai sensori. Ciò elimina la necessità di trasmettere dati su lunghe distanze ai server remoti del Cloud, riducendo significativamente la latenza. Questa bassa latenza è essenziale per applicazioni in tempo reale come il controllo industriale, la guida autonoma e la realtà virtuale, migliorando notevolmente l’efficienza e la reattività dei sistemi.
- Dipendenza dalla Connessione Internet: Il Cloud richiede una connessione Internet costante, mentre l’Edge Computing funziona anche offline, garantendo continuità operativa.
- Controllo sull’Infrastruttura: Nel Cloud, hai meno controllo sull’infrastruttura sottostante, poiché è gestita dal provider. Con l’Edge Computing, hai maggiore controllo su hardware e sul software.
- Sicurezza e Privacy: Il Cloud può presentare rischi di sicurezza dovuti alla memorizzazione dei dati su server remoti. L’Edge Computing può offrire un maggiore controllo sulla sicurezza, poiché i dati rimangono locali.
- Costi Operativi: Il mantenimento di server remoti nel Cloud può comportare costi operativi elevati, mentre l’Edge Computing può essere più economico in particolare per piccole implementazioni locali.
- Complessità della Gestione: La gestione di ambienti Cloud complessi può richiedere competenze specializzate, mentre l’Edge Computing può essere più semplice da gestire localmente.
Certo tutto questo può essere solo un parere soggettivo determinato dalle mie personali esperienze lavorative, per altre persone potrà essere l’esatto contrario, rimango comunque dell’avviso che ciò di cui ho parlato descrive, in un paragone calzante, le stesse problematiche che il mondo sta affrontando per l’eccessiva deindustrializzazione dell’occidente che ha deciso decenni addietro di esternalizzare i processi produttivi sull’onda del concetto di “globalizzazione”, per il quale si è arrivati oggi ad essere dipendenti dei nostri fornitori (vedi la Cina solo per fare l’esempio più lampante) senza i quali non potremmo assemblare un PC o un telefonino, produrre abbastanza energia elettrica etc….
Alla fine un’azienda non è così diversa da uno Stato, lo Stato per essere definibile come tale deve avere un popolo che lo contraddistingue ed un territorio su cui esercita la sua sovranità; un’azienda necessità di proprio personale che apporta lavoro ed intelletto, che crea e genera idee da cui scaturiscono know-how e magari anche brevetti e deve essere la proprietaria di tutto ciò che produce e/o trasforma, altrimenti per entrambi i casi parliamo solo di “Colonie”.