Durante la preparazione del secondo articolo su #Bitcoin 1 anno di studio, ho riflettuto su alcune considerazioni che spesso si fanno al volo nel momento in cui si sentono determinate notizie su prossimi fenomeni sociali e/o sconvolgimenti degli assunti modelli di Status quo.
Quasi come una profezia sul futuro, o forse come un monito al cambiamento sociale verso cui ci stanno spingendo, uno dei nuovi mantra più rilevanti lo ha da tempo messo in agenda il World Economic Forum, che già dal lontano 2017 ha iniziato a proporre un messaggio che potremmo tradurre in questa immagine:

Letto velocemente e senza riflettere su quali siano le evidenze della nostra vita quotidiana di Occidentali privilegiati, sembra una forzatura, ma se provassimo ad analizzare insieme ciò che abbiamo attorno, potremo vedere che i semi di questo frutto avvelenato stanno gi crescendo nell’humus della nostra società, una società che, rispetto a quella dei nostri nonni o anche solo dei nostri genitori (intendendo perlomeno i baby boomers, dunque persone nate tra il 1945 ed il 1965), è stata spinta ad un sostanziale distacco dalla condivisione dei problemi della comunità, creando una sorta di noncuranza apatica, che negli ultimi 2 anni si è trasformata in “distanziamento”.
Un cambiamento sociale che nel dopo guerra era sinonimo di mutuo soccorso tra le persone, e che invece oggi ha assunto il ben più lugubre significato di : “…tutto è stato trasformato in intrattenimento e le persone non hanno più voluto preoccuparsi di problemi difficili”, ossia di quei problemi, politici, industriali, economici che sembrano così complicati al punto che finiamo col pensare che “non sono affar nostro” e che, per organizzare e gestire i quali, si debba delegare tutto agli esperti, ai tecnici, agli scienziati (i virologi), gli amministratori delegati, i grandi finanzieri, i media mainstrem, i moralizzatori… “…sapranno ben loro occuparsi di tutto per noi, assicurandoci la felicità”.
Io ho trascorso infanzia e giovinezza tra gli anni 70-80 e le case erano piene di dischi in vinile, musicassette, video cassette, cartucce di video giochi, album fotografici etc……; quindi possedevamo fisicamente le nostre collezioni di arte nelle sue differenti forme.
Ma OGGI ??
- la Musica la “paghiamo” (non la compriamo) su Spotify;
- i Film li vediamo in streaming da Netflix, Disney channel etc…..;
- i Video giochi si stanno spostando su piattaforme di streaming online e a breve sui Metaversi;
- le Fotografie sono tutte nel cloud tra servizi Social come FB o Instagram che usiamo come store (magazzino) della nostra vita
- i Documenti li scriviamo, li condividiamo su piattaforme come GoogleDocs;
- i Progetti sono parcheggiati su piattaforme cloud come Github
- i Server aziendali sono quasi tutti nel cloud di AWS e simili, tra macchine virtuali senza alcuna identità
e potrei continuare ancora a lungo. Dunque che cosa succede se e quando uno di questi servizi ha problemi di connessione di qualunque genere, e negli ultimissimi anni è capitato un pò a tutti i Big del Cloud di avere delle cadute di servizio improvvise, a volte anche di diverse ore. Abbiamo così visto uffici impossibilitati a gestire i documenti, le fatture, le spedizioni o solo a mandare email , riunioni annullate, disservizi di ogni genere in ambito lavorativo/professionale. E nella vita personale ??, cosa succede se Netflix non funziona o non riesci a rinnovare l’abbonamento? come la ascolti la musica se Spotify ti chiude l’utenza, magari per sbaglio, magari per altri motivi, che fine fa tutto il lavoro di creazione delle tue splendide Playlist?, perso in un attimo, e le foto di una vita ?, le vacanze, il primo giorno di scuola dei figli etc…. cosa accade se Facebook cambia il regolamento delle politiche aziendali e magari!! a causa di quel post in cui hai criticato l’ultima iniziativa del governo vieni segnalato ed il tuo account viene sospeso o cancellato?
Questa lunga premessa era d’obbligo per cercare di farvi entrare nel ragionamento per cui personalmente penso che il Web 2, quello che viviamo ancora oggi, si sia strasformato in un sistema ultra centralizzato in cui pochi attori decidono le sorti dei loro utenti, altro che il motto “il cliente ha sempre ragione”, qui il cliente può solo fare ACCETTA ad ogni aggiornamento di regolamento del Social di turno, oppure finire estromesso dalla sua esistenza virtuale, SI perchè siamo noi, tuenti e creator che creiamo i contenuti dei loro Social ma i padroni di quei contenuti, stranamente, non siamo noi ma sono loro.
Ma come siamo arrivati a questo e perchè nutro la speranza che il web3 possa riportarci ai fasti del web1 ma con in più l’innovazione e l’accento sulla proprietà personale delle informazioni.
L’evoluzione di Internet
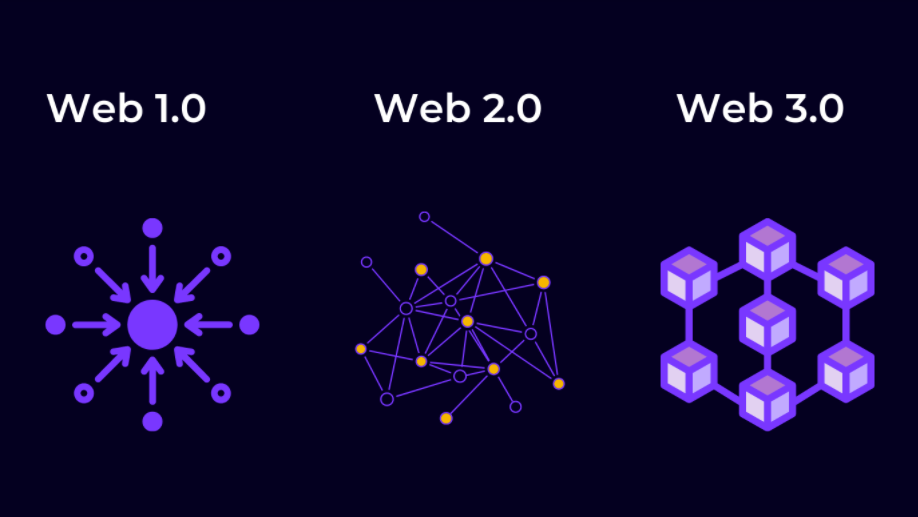
WEB 1.
Il web1 , che possiamo inquadrare nel periodo che va, all’incirca, tra il 1990 ed il 2005, riguardava fondamentalmente la nascita e la prolificazione dei protocolli del web aperti, decentralizzati e governati dalle community, certo la comunicazione era unidirezionale ma chiunque poteva aprirsi un sito, un blog e condividere i propri interessi senza censura.
Tutto ciò significava che, inizialmente, le persone o le aziende potevano aumentare la loro presenza su Internet sapendo che le regole del gioco non sarebbero cambiate in seguito. In questa prima fase sono così nati i più importanti soggetti del web quali Yahoo, Google e Amazon.
WEB 2.
Con il web2 (all’incirca 2005-2020) si sono successivamente sviluppati tutta una serie di servizi centralizzati gestiti da società che si sono trasformate in Monopolio del web. La maggior parte del valore è stato acquisito da una manciata di aziende come Google, Apple, Amazon e Facebook, avvantaggiate dalla crescita esplosiva degli smartphone che ha generato la tendenza all’uso delle app, che sono diventate ad oggi la maggior parte dell’uso quotidiano di Internet. Questo ha fatto si che alla fine gli utenti sono migrati dai servizi aperti a questi servizi centralizzati, inizialmente più sofisticati.
Bene ma non BENISSIMO; certamente questo ha fatto si che miliardi di persone abbiano avuto accesso a tecnologie straordinarie, molte delle quali erano gratuite ma, la cattiva notizia è che è diventato molto più difficile per startup, senza appoggio di Venture Capitalist, riuscire ad aumentare la propria presenza su Internet senza preoccuparsi che le piattaforme centralizzate cambiassero le regole su di loro in corso d’opera, portandogli via pubblico e profitti. Di riflesso, anche se potrebbe non sembrare, questo ha soffocato l’innovazione, rendendo Internet meno interessante e dinamico. La CENTRALIZZAZIONE ha anche, in seconda battuta, creato tensioni sociali più ampie, generando un sistema di controllo e censura del web che ritroviamo in concetti come fake news, fact checker , privazione della privacy degli utenti per un bene più alto e tanto altro.
Ci troviamo in questo momento storico all’inizio di un nuovo paradigma, poichè stiamo vivendo la nascita dell’era web3, che combina l’etica decentralizzata e governata dalla community del web1 con le funzionalità avanzate e moderne del web2.
WEB 3.
Il web3 è l’Internet della proprietà e degli utenti, non più delle multi nazionali della Silicon Valley, dove il tutto viene orchestrato attraverso i #token. Innanzitutto, diamo un’occhiata ai problemi delle piattaforme centralizzate.
Le piattaforme centralizzate seguono un ciclo di vita prevedibile e, all’inizio, fanno tutto il possibile per reclutare utenti per formare una community e creatori di contenuti da eleggere ad influencer, cercano il sostegno di grandi Brand così da poter rafforzare il loro effetto e la loro presenza in rete.
Man mano che le piattaforme aumentano la curva di adozione, il loro potere sugli utenti e sulle terze parti cresce costantemente, a tal punto che una volta raggiunta la vetta della curva di crescita/adozione, le loro relazioni con i partecipanti alla rete si azzerano, trasformando i propri partner in competitor: esempi famosi di questo sono Microsoft contro Netscape, Google contro Yelp, Facebook contro Zynga etc, e gli utenti che hanno formato la massa di adozione vengono controllati con sempre più aggiornamenti dei regolamenti della community, che di community a questo punto hanno ben poco visto che non esiste una votazione per la decisione delle modifiche e se vuoi rimanere nel Social puoi solo che cliccare sul campo “accetta”, altrimenti verrai buttato fuori in tempo zero.
Dunque una forma di controllo delle masse basato sul consenso forzato delle “regole della community” ; si arriva così, solo dopo, a capire che che i Social sono solo aziende private con le loro policy aziendali ed i loro interessi commerciali, non sono centri sociali di scambio e divulgazione del pensiero libero democratico.
La Speranza nasce dal fatto che nel web3, la proprietà e il controllo sono decentralizzati, ciò significa che gli utenti possono partecipare attivamente nei progetti, insieme ai costruttori delle nuove piattaforme, possedendo pezzi di servizi Internet tramite il possesso di token, sia non fungibili (NFT) che fungibili (come le criptovalute). I token conferiscono agli utenti dei diritti di proprietà: questi diritti possono riguardare arte, foto, codice, musica, testi, oggetti da gioco, credenziali, diritti di governance, pass di accesso, e, in linea generale, tutto ciò che la gente può immaginare.
BENVENUTI NELLA RIVOLUZIONE DEL WEB 3
Nel prossimo articolo continueremo su questa traccia iniziando a descrivere il mondo del Branding e degli NFT.