Bitcoin spiegato semplice: la moneta del futuro, nata dalla crisi del passato
Premessa: il libro da cui parte questo primo capitolo/articolo è “Il Bitcoin Standard” di Saifedean Ammous (professore di economia alla Lebanese American University e membro del Center on Capitalism and Society della Columbia University), è un testo uscito ormai nell’estate del 2018 ma che non è mai stato abbastanza pubblicizzato, o quanto meno in Italia che, rispetto ad altre nazioni europee è quella in cui meno si studia l’argomento Economia, salvo di non aver frequentato a livello accademico scuole blasobate e specializzate come la Bocconi in cui gli studi sono verticali sulla Finanza e sulla specializzazione bancaria.
Prima di avventurarci nell’introduzione di questo testo, analizziamo velocemente la situazione alquanto particolare dello studio della materia economica nel sistema scolastico italiano.
📚 Educazione Economica nelle Scuole dell’Obbligo
Situazione Attuale
Assenza nel Curriculum: Fino al 2024, l’educazione finanziaria non era parte integrante del curriculum scolastico italiano. Solo recentemente è stata introdotta come parte dell’educazione civica, grazie a una legge approvata dal Parlamento.
Secondo il documento sotto linkato presentato a Giugno 2024 dell’OCSE (Organizzazione per la Cooperazione e lo Sviluppo Economico), tramite il loro programma d’indagine internazionale P.I.S.A. (Programme for International Student Assessment) che coinvolge 79 Paesi, risultata che l’alfabetizzazione finanziaria in Italia non è esattamente ai massimi livelli, infatti gli studenti italiani hanno ottenuto in media 484 punti, un punteggio inferiore alla media OCSE in materia di alfabetizzazione finanziaria (498 punti). Circa il 18% degli studenti in Italia non raggiunge il livello base di competenza (Livello 2) in materia di alfabetizzazione finanziaria. Questo vuol dire che, nella migliore delle ipotesi, questi studenti sono in grado di identificare i prodotti e i termini finanziari più comuni, di riconoscere la differenza tra bisogni e desideri e di prendere semplici decisioni sulle spese quotidiane in contesti che probabilmente hanno incontrato personalmente. In Italia solo circa il 5% degli studenti raggiunge i massimi livelli (livello 5) di alfabetizzazione finanziaria, rispetto all’11% della media dei Paesi e delle economie dell’OCSE. PISA 2022 Results (Volume IV) – Factsheets: Italy
🎓 Educazione Economica nelle Università
Orientamento dei Corsi
Focus su Finanza e Management: Università prestigiose come la Bocconi offrono corsi incentrati su finanza, amministrazione e marketing, con meno enfasi su macroeconomia o economia politica .
Offerta Limitata in Economia Politica: Sebbene esistano corsi di economia politica, la tendenza generale è verso programmi applicati e orientati al mercato.
Tasso di Istruzione Terziaria
Basso Tasso di Laureati: Solo il 13% degli italiani tra i 25 e i 64 anni ha completato l’istruzione terziaria, rispetto a una media OCSE del 24% .FIRSTonline
Spesa per Studente: L’Italia investe 13.717 dollari per studente nell’istruzione terziaria, al di sotto della media OCSE di 17.559 dollari.
📊 Confronto Internazionale
Spesa per l’Istruzione
Percentuale del PIL: L’Italia destina il 4% del PIL all’istruzione, inferiore alla media OCSE del 4,9%.
Alfabetizzazione Finanziaria
Risultati PISA: In Italia, gli studenti mostrano competenze finanziarie inferiori rispetto a coetanei in paesi come gli Stati Uniti e i Paesi Bassi.
📌 Conclusione
In conclusione è evidente che l’Italia si trova in una posizione di svantaggio rispetto ad altri paesi europei e agli Stati Uniti per quanto riguarda l’educazione economica e finanziaria.
Introduzione – “Il Bitcoin Standard”
Che cos’è il denaro? E perché dovrebbe interessarci una moneta virtuale creata da un misterioso personaggio chiamato Satoshi Nakamoto? In un mondo scosso da crisi economiche, inflazione e perdita di fiducia nelle istituzioni, Bitcoin si presenta come un’alternativa radicale: una moneta nata per essere indipendente, libera e programmabile. Ma cosa significa davvero? E come può cambiare la nostra vita quotidiana?
1. Le radici della crisi: perché è nato Bitcoin
Nel 2008 il mondo ha assistito a una delle più gravi crisi finanziarie della storia recente. Le banche, che avrebbero dovuto essere custodi del risparmio e del credito, hanno mostrato tutta la loro fragilità. Milioni di persone hanno perso il lavoro, la casa, la fiducia nel sistema.
Proprio in quell’anno, mentre i governi salvavano le banche con denaro pubblico, nasceva un’idea rivoluzionaria: Bitcoin. Nel primo blocco della sua blockchain è inciso un messaggio che è diventato il manifesto di questa nuova moneta:
“The Times 03/Jan/2009 Chancellor on brink of second bailout for banks.”
Un atto di accusa contro il sistema finanziario, ma anche una dichiarazione d’intenti: creare un’alternativa che non dipendesse da governi, banche o istituzioni centrali.
2. Cos’è Bitcoin (e cosa non è)
Bitcoin non è un oggetto fisico. Non è un’app, né un “gettone” virtuale da collezionare. Bitcoin è un protocollo: un insieme di regole informatiche che permettono a una rete di computer di scambiarsi valore in modo sicuro, trasparente e senza intermediari.
Come Internet ha rivoluzionato la comunicazione, Bitcoin vuole rivoluzionare il denaro. E come Internet, non ha un amministratore centrale: nessuno può spegnerlo, censurarlo o modificarlo arbitrariamente.
3. Le tre componenti fondamentali di Bitcoin
Per capire come funziona Bitcoin, bisogna conoscere le sue tre componenti chiave:
La blockchain: è un registro pubblico e immutabile, in cui sono registrate tutte le transazioni effettuate. Ogni “blocco” è una pagina del registro. Una volta scritta, non si può più modificare.
I nodi: sono computer che eseguono il software Bitcoin e controllano che tutte le regole vengano rispettate. Chiunque può diventare un nodo, contribuendo alla sicurezza e alla trasparenza del sistema.
I miner: sono i computer che competono per aggiungere nuovi blocchi alla blockchain. Risolvono complessi problemi matematici e, in cambio, ricevono nuovi bitcoin come ricompensa. È così che nuovi bitcoin vengono “emessi” nel sistema.
4. Le regole del gioco: inflazione programmata
Bitcoin è stato progettato per essere scarso. A differenza delle valute tradizionali, che possono essere stampate a piacimento, Bitcoin ha un limite massimo: ne esisteranno solo 21 milioni. Inoltre, ogni quattro anni circa, la quantità di nuovi bitcoin emessi si dimezza (evento chiamato halving).
Questo meccanismo crea una forma di inflazione decrescente, prevedibile e non manipolabile. Nessuna banca centrale può cambiarlo. Nessun politico può decidere di “creare” nuovi bitcoin.
5. Perché Bitcoin è diverso da tutto il resto
Bitcoin non ha un CEO. Non ha un’azienda dietro. Non ha marketing. Non ha una sede. È un protocollo aperto, disponibile a tutti. Chiunque può usarlo, modificarlo, studiarlo. Ed è per questo che funziona: non dipende dalla fiducia in una persona, ma dalla trasparenza del codice.
È resistente alla censura: nessuno può impedirti di usarlo. Non serve un conto in banca. Serve solo una connessione a Internet e la volontà di imparare.
6. Le implicazioni sociali, politiche e culturali
Bitcoin è anche un atto politico. Non nel senso di un partito, ma nel senso più profondo del termine: è una scelta di come vogliamo organizzare la fiducia nella società.
In molti paesi, Bitcoin rappresenta un’ancora di salvezza contro l’iperinflazione, la censura finanziaria, la corruzione. Permette a milioni di persone escluse dal sistema bancario di partecipare all’economia globale.
E per chi vive in paesi stabili, Bitcoin è comunque uno strumento di educazione finanziaria, consapevolezza, responsabilità.
7. Il futuro: perché potrebbe durare
Bitcoin esiste da oltre 15 anni. Funziona. Ha superato attacchi, critiche, crolli di prezzo. E continua a crescere.
Oggi esistono migliaia di nodi sparsi in tutto il mondo. Il codice migliora. Le tecnologie di secondo livello, come Lightning Network, lo rendono veloce ed economico per i pagamenti quotidiani.
E più tempo passa, più aumenta la sua credibilità. È il cosiddetto “effetto Lindy”: ciò che esiste da molto tempo ha maggiori probabilità di esistere anche domani.
Conclusione
Bitcoin non è una moda passeggera. Non è un investimento facile. Non è una scorciatoia per arricchirsi. È una tecnologia profonda, che pone domande scomode e propone soluzioni radicali.
E oggi più che mai, in un mondo sempre più digitale, sorvegliato e instabile, Bitcoin rappresenta una possibilità concreta: per avere più libertà, più sovranità, più futuro.
La domanda è: vorresti farne parte?
Per approfondire:
“Inventing Bitcoin” – Yan Pritzker
“The Bitcoin Standard” – Saifedean Ammous
bitcoin.org/it, github.com/openoms
Documentario: “The Rise and Rise of Bitcoin”
Nei prossimi articoli analizzeremo i concetti e gli esempi descritti all’interno del libro, del quale consiglio comunque caldamente la lettura.
Moneta, soldi, money, piccioli, palanche, danè……. comunque lo chiamate è una parte importante, direi fondamentale della vita di ciascuno di noi, in particolare oggi ed a partire dalla rivoluzione industriale; si perchè prima per poveri che si potesse essere, un pezzo di terra in cui coltivare verdura, 4 galline per le uova, una mucca o due capre per del latte, si riuscivano ad avere come dote/benessere primario di una famiglia, ma oggi? oggi se non hai denaro in un conto in banca non puoi accedere a nulla, non puoi usufruire di nessun servizio, non esisti a livello sociale perchè quella di oggi è una società dell’economia, della finanza, in cui il concetto di “SOCIALE” è ormai quasi scomparso dal significato di società. Quindi per triste che possa sembrare quando ci soffermiamo a pensarci, la realtà delle cose è che la maggior parte di noi lavora almeno 8 ore al giorno, 5 giorni alla settimana (quando va bene) per accedere alla propria piccola fetta di “benessere”. La nostra vita che ci piaccia o meno si sviluppa attorno a questo strumento che è apparentemente fondamentale per la sopravvivenza di tutti i giorni.
Chi non ha mai sognato di avere la possibilità di “stamparsi” il denaro di cui avrebbe bisogno; io la prima volta ci pensai mentre guardavo il film ” la banda degli onesti” con Totò e Peppino e pensarlo sembrava strano, sia perchè avrò avuto 8 anni, sia perchè per quel poco che ne sapevo era lo Stato che stampava i soldi presso la Zecca; ma comunque significava che se sei il possessore DELLA STAMPANTE hai il potere di crearti i soldi, soldi che a quel punto sono “regolari”, sono Valuta di Stato.
Un esempio chiaro di questo concetto l’ha introdotto la serie TV Netflix “ la casa di carta” il cui piano non è di falsificare le banconote ma di stamparsele direttamente alla fonte per cui per il SISTEMA diventerebbe praticamente impossibile escludere dal mercato tutto quel valore cartaceo senza gravi ripercussioni. In cuor mio credo che quella serie abbia fatto risvegliare anche alcuni tra coloro che il Denaro lo creano e lo gestiscono e che abbia forse accelerato l’idea della creazione della “valuta digitale” l’ormai nota CBDC, ossia la Central Bank Digital Currency, destinata a diventare la nuova valuta, ma soprattutto “programmata” nella sua distribuzione e validità; ma di questo ne parleremo meglio più avanti.
In pratica abbiamo appena esaminato, alla veloce, il fatto oggettivo che il nostro mondo è governato non dal, ma con il denaro. Eppure ci facciamo pochissime domande sul funzionamento di esso e dell’economia in generale. Per esempio:
Chi lo crea?
Chi possiede questo potere?
Perché lo Stato, se vuole finanziare la spesa pubblica, non stampa direttamente denaro ma per esempio chiede un debito, un prestito, a quella che è la Banca Centrale?
Cos’è? Come funziona?
Come funziona la stampa di denaro?
Che cosa è ; come funziona il signoraggio bancario?
Qual’è il ruolo delle Banche?
Che cosa è la riserva frazionaria?
Ecco, oggi proveremo a parlare di questo e di molto altro ancora…..
BREVE STORIA DEL DENARO
Cominciamo dal punto di vista storico parlando di denaro ovvero come è stato creato il denaro quali sono le prime forme di denaro che abbiamo visto all’interno della storia; sappiamo che in antichità non esisteva la moneta infatti all’inizio le persone utilizzavano come mezzo di scambio economico quelli che erano piccole conchiglie, pezzi di vetro lavico, grosse rocce, asce, o qualsiasi tipo di mezzo che potesse essere scarso che potesse essere duraturo nel tempo e che quindi conservasse quella che era la sua forma di valore.
E’ inutile provare a datare la nascita dei primi che hanno fatto uso di scambio e/o commercio tramite una qualunque delle forme di valuta sopra indicate perchè ci sono costantemente scoperte storiche che farebbero spostare e retrodatare la datazione storica, dunque ci atteniamo per i nostri esempi alla Storia attuale che ci indica come l’uomo utilizzasse già 4000/5000 anni fa una forma di scambio, prima tra tutte potrebbe essere stata il Baratto, una forma di pagamento che ancora ai giorni nostri trova il suo spazio all’interno di determinate community. Il Baratto, dicevamo era certamente una delle prime forme più semplici a cui si potesse arrivare naturalmente per scambiarsi beni ma che soffre di quattro caratteristiche fondamentali:
la doppia coincidenza dei bisogni o dei desideri
assenza di coincidenza di scala
assenza di coincidenza temporale
assenza di coincidenza di luogo
Nel primo caso abbiamo semplicemente il fatto che ciò che si vuole acquistare è prodotto da chi non è interessato a venderlo o non è interessato a ciò che noi possiamo vendergli.
Nel secondo caso stiamo cercando di barattare un bene di valore assai differente dal bene che stiamo offrendo in cambio, la cosa diventerebbe ulteriormente impossibile da realizzare se il bene di maggiore valore fosse anche indivisibile, dunque non frazionabile in unità più piccole, ad esempio io vendo Mele e vorrei scambiarle con una Spada, la spada ha un valore maggiore delle mie mele e non posso farmi dare solo un pezzo di spada poichè non è divisibile.
Nel terzo caso stiamo offrendo un bene deperibile in cambio di un bene che invece ha un alto tempo di durabilità, per esempio, mettiamo che io possegga ettari di mele da poter raggiungere il valore della spada ma accettando lo scambio chi riceve le mele a breve si ritroverebbe con una grande quantità di materiale deperibile (le mele marciranno) ed inservibile mentre la spada che avrò acquistato durerà decenni;
Nel quarto caso abbiamo una casa di pregio in città ma vorremmo trasferirci al mare, dovrò trovare una casa di valore similare alla mia ma soprattutto, una volta trovata la giusta sistemazione l’attuale padrone dovrà avere l’intenzione di andare a vivere in città nello stesso momento in cui io mi vorrei spostare al mare; quest’ultimo esempio lo vediamo oggi sulle piattaforme di scambio vacanze in cui chi ha un’abitazione in una grande città o chi ce l’ha in un luogo di mare, magari anche turistico, riesce più facilmente a trovare uno scambio equo in una data che possa andare bene ad entrambe le parti, etc……
Altro caso storico interessante è stato quello della moneta Rai dell’isola di Yep, grossi dischi circolari di pietra usato come denaro per via della loro scarsità, durata nel tempo e valore dato dalla fatica necessaria a costruirle, una sorta di PoW (Proof of Work). Ora facciamo un salto storico e spostiamoci al momento in cui sono nate quelle che sono le vere e proprie monete quindi la forma fisica dell’oro dell’ argento che venivano utilizzati come mezzo di scambio dalle persone. La “moneta” era nata per creare una sorta di standard nei vari mezzi di scambio tra le persone poichè andare in giro con un bilancino idrostatico per pesare l’oro (oltre al fatto che all’epoca ancora non esisteva) o trovare comunque dei modi per verificare che la moneta, il pezzettino d’oro, non fosse falsificato era estremamente difficile è per questo che già dall’antica Grecia e poi anche i romani hanno cominciato a coniare la moneta quindi a creare pezzi di dimensioni standard d’oro con al di sopra rappresentato un valore nominale, quindi una rappresentazione numerica del valore del pezzettino di metallo; in realtà fin dall’inizio il valore nominale stampato al di sopra della moneta non rappresentava il reale valore del peso del metallo prezioso questo perché il diritto di coniare moneta veniva solitamente dato solamente ai signori, agli imperatori, in alcuni momenti della storia ad alcune piccole aggregazioni religiose, ma di fatto era un mezzo monopolistico in cui delle entità dominanti coniavano questi pezzettini di metallo, gli stampavano sopra un valore nominale, lo rendevano estremamente più difficile da falsificare rispetto a un semplice lingottino e si facevano pagare per questo, infatti solitamente c’era una discrepanza tra quello che era il valore della lega metallica, il suo peso e il valore nominale, ossia il valore impresso al di sopra del pezzo, questa differenza era il prezzo il costo del servizio dato al coniatore della moneta stessa, ed infatti il suo lavoro veniva detto l’aggio del signore, o signoraggio. Questo è il signoraggio bancario ovvero il guadagno che ha un ente nell’emissione di carta moneta la pura differenza fra valore nominale impresso al di sopra della moneta e il valore reale che ha il pezzo fisico che viene utilizzato come mezzo di scambio. Facciamo nuovamente un salto avanti nel tempo, immaginatevi, siamo nella Venezia del 1500 ed in un contesto sociale come questo immaginate di essere lì con le vostre belle monete d’oro e dovete andarle a depositare perché è rischioso andarci in giro se avete tanti soldi in tasca, non vorreste mai essere derubati o comunque correre dei rischi; quindi cosa fate? li andate a depositare in un banco, e cosa erano i banchi al tempo di Venezia? erano quelle che sono oggi le attuali banche. All’inizio queste istituzioni sono nate come punto di exchange/cambio per le varie valute presenti nei vari stati del vecchio continente europeo, poi negli anni hanno cominciato anche a offrire ulteriori servizi come per esempio deposito bancario trasferimento di denaro, per esempio molto famosi furono i Templari, questa organizzazione permetteva il deposito di quella che era la moneta d’oro e in cambio rilasciavano quella che era una ricevuta del deposito, con questa “nota di banco” presentandosi presso altri banchi convenzionati era possibile mostrare la ricevuta e ritirare il proprio oro presso un altro deposito da un’altra parte del mondo. Questi servizi sono certamente molto interessanti ed il loro utilizzo e sviluppo si espande molto in fretta; a questo punto questi banchi cominciano ad avere un sacco di moneta nelle loro casse, come risultante la gente comune comincia ad utilizzare le ricevute (le note di banco) di questi anticipatori delle banche come vera moneta di scambio questa specifica ricevuta diventerà la Banconota.
Parlando di banchieri a Venezia vale assolutamente la pena menzionare la famiglia Del Banco ovvero una famiglia anzi la prima famiglia di banchieri veneziani di origine ebraica; il capostipite Anselmo Del Banco era uno degli uomini più ricchi dell’ intera Venezia cinquecentesca e aveva ricevuto dal governo il permesso di prestare denaro con interesse, permesso che però venne vietato in seguito alla comunità ebraica sia in ambito finanziario che anche in altri ambiti economici, viene di conseguenza tolto questo potere e la famiglia Del Banco si trasferisce fuori dalla Repubblica di Venezia (dall’italia) dove può applicare interessi ai suoi prestiti e quindi si trasferiscono nella piccola cittadina di Warburg dalla quale successivamente prenderanno e cambieranno il loro cognome quindi i Warburg sono una delle attuali dinastie di banchieri più potente e antica della storia. Da qui in avanti moltissime famiglie di origine ebrea diventareanno importanti e facoltosi banchieri, questo perchè l’espansione dei banchi (future banche) dava loro un grande vantaggio poichè da sempre essi utilizzato la formula del prestito con interesse, i riferimenti li possiamo trovare nella Bibbia, nella Torah ebraica per esempio citiamo Deuteronomio 23 (Non farai al tuo fratello prestiti a interesse, né di denaro, né di viveri, né di qualunque cosa che si presta a interesse. 21 Allo straniero potrai prestare a interesse, ma non al tuo fratello, perché il Signore tuo Dio ti benedica in tutto ciò a cui metterai mano, nel paese di cui stai per andare a prender possesso) . Dunque gli ebrei hanno sempre utilizzato all’interno della storia il prestito con usura o alto interesse, invece la dottrina della chiesa cristiana figlia del pensiero neoplatonico ha sempre proibito il prestito con interesse, Platone si è sempre espresso contrario all’usura così come Aristotile, Catone, Seneca, Cicerone e lo stesso Buddha si sono sempre espressi contro l’interesse con usura o in generale un alto interesse bancario.
Tornando alla funzione e all’uso dei Banchi, all’epoca vigeva ancora quello che era il sistema aureo quindi la stampa della moneta era fatta direttamente con l’oro dunque non c’era quella che è oggi la stampa di una moneta che non ha un valore intrinseco, inoltre quando si depositava la propria moneta all’interno dei banchi questi comunemente effettuavano quella che è la riserva frazionaria ma con percentuali estremamente diverse a quelle di oggi, per esempio all’epoca (1500/1600) si riteneva più o meno normale detenere una riserva del 70% circa all’interno delle banche, ovvero la banca teneva all’interno di essa circa il 70 per cento del controvalore depositato dai propri clienti, questo era per l’epoca un rapporto ritenuto buono per garantire una certa liquidità ai propri clienti ma allo stesso tempo una certa liquidità alla banca con cui investire e quindi guadagnare dai propri servizi.
Va ancora ricordato che la stampa di monete era principalmente in mano a grandi enti centralizzati o comunque a Stati, Imperatori, Governi, Città Stato etc… ; mano mano che passa il tempo nel corso dei secoli i banchi si trasformano in banche diventando sempre più potenti ed anche la stampa di moneta si centralizza sempre più all’interno di grossi stati e governi, diventando loro stessi fautori della stampa di denaro. Man mano che il denaro si centralizza sempre più l’oro tende a scomparire, mentre l’utilizzo delle banconote si afferma sempre di più………; arriviamo così nella Londra del 1800, qui infatti la situazione si è evoluta così tanto rispetto a quella del sedicesimo secolo italiano che addirittura molti economisti cominciano a criticare quella che è la stampa e la eccessiva emissione di carta moneta in quanto contestano il fatto che questa provoca una diminuzione del potere d’acquisto e quindi un innalzamento dell’inflazione dei prezzi tale che nel 1844 il governo britannico emanò il Bank Charter Act che stabiliva che la facoltà di stampare carta moneta fosse riservata solamente alla banca centrale di Inghilterra.
Si desume che con quest’atto si giunga alla nascita del Gold standard del XIX secolo, infatti l’emissione di nuove banconote doveva essere coperta da un uguale ammontare d’oro. La gran bretagna adotta questo gold standard seguita poi dall’impero germanico ( il secondo reich) e poi piano piano tutti gli altri paesi europei seguiranno questa nuova forma di stampa di denaro e in coda arriveranno anche gli stati uniti. Per quello che riguarda gli USA, la differenza rispetto agli stati europei è che quest’ultimi non avevano in realtà una banca centrale come la maggior parte degli stati europei, infatti dalla firma della Dichiarazione d’indipendenza, già due presidenti americani ovvero Thomas Jefferson e Andrew Jackson si erano espressi contrari alla presenza di un forte sistema bancario centrale dominato da grandi dinastie, come per esempio i Rotschild ed i Walburg, essi avevano quindi stroncato sul nascere i precedenti tentativi di creazione di una banca centrale, anche se noi oggi conosciamo la FED.
Ma vediamo quali son stati allora i fatti storici che hanno portato alla fine alla formazione della FED, e come avrebbero detto gli antichi romani: “cui prodest”? (a chi ha giovato?).
Il peccato originale della Federal Reserve
Come appena accennato negli USA due Presidenti avevano bloccato la creazione di una Banca centrale per evitare di dare troppo potere economico/finanziario nelle mani di poche persone, ma il gioco era troppo importante ed appetitoso per fermarsi, così il 22 novembre 1910 nella stazione ferroviaria di Brunswick stato della Georgia, ci sono sette individui che scendono da un treno tutti travestiti da cacciatore di anatre con fucili giacche da caccia e tutto il necessario che serve a non destare troppa attenzione; il capo stazione, pre allertato, li riconosce e li avvisa che nei dintorni potrebbero esserci dei giornalisti; chi sono questi sette uomini travestiti che scendono dal treno? stando alla versione ufficiale e alle testimonianze troviamo nell’ordine: il senatore repubblicano Nelson Aldrich, capo della Commissione Monetaria nazionale; A. Piatt Andrew, assistente del Segretario al Tesoro; Frank Vanderlip, presidente della City National Bank di New York, nonchè braccio destro di William Rockefeller; Henry P. Davidson senior, partner anziano della JP Morgan Company e indiscusso alter ego di mister John Pierpont Morgan in persona; il suo collega Benjamin Strong, capo della JP Morgan Bankers Trust; Charles D. Norton, presidente della First National Bank di Manhattan e Paul M. Warburg, partner della Khun, Loeb & Company, rappresentante delle famiglie Warburg e Rotschild in Europa.
Il Luogo : luogo prescelto per questo importante incontro è Jekyll Island, un isolotto divenuto dal 1886 l’invidiabile resort privato delle più facoltose famiglie dell’establishment Usa: dai Morgan ai Vanderbilt, dai Pulitzer ai Carnegie, dai McCormick ai Rockefeller; nella pratica questo resort era un luogo così esclusivo che il Munsey’s Magazin nella sua edizione del 1904 non esitava a definire: “the richest, the most exclusive, the most inaccessible” club in the world, ossia il più ricco esclusivo e inaccessibile club al mondo; quindi per dieci giorni questi simpatici signori della finanza discuteranno a porte chiuse di una cosa per loro molto importante ovvero la creazione della fed, la federal reserve, una banca centrale privata che prendesse il controllo del Dollaro statunitense. Ma non tutto fila liscio, nonostante il peso dei soggetti d’accordo alla formazione della banca centrale, ci sono altri tre personaggi di peso che non sono in accordo alla sua realizzazione, questi tre antagonisti sono imprenditori molto importanti nell’economia degli stati uniti di quegli anni ovvero:
John Jacob Astor IV: imprenditore, inventore, scrittore, membro di spicco della dinastia degli Astor, costruì i famosi alberghi St. Regis e Knickerbocker di New York e fu proprietario del celebre Waldorf-Astoria Hotel, una delle vittime del naufragio del Titanic;
Isidor Straus: imprenditore e politico tedesco naturalizzato statunitense co-proprietario, insieme al fratello, della catena di distribuzione Macy’s di New York, una delle vittime insieme alla moglie del naufragio del Titanic;
Benjamin Guggenheim: erede del patrimonio del padre Meyer Guggenheim, magnate minerario, sposato con Florette Seligman Guggenheim, figlia di James Seligman Presidente della New Yorker Investment Bank, una delle vittime del naufragio del Titanic.
Come forse avrete notato i tre personaggi in questione hanno in comune, oltre l’essere contrari alla creazione della FED quella di essere tutti morti nel naufragio del Titanic nel 1912. Qui entra in campo il “cui prodest?” . I fatti sono questi, poi vedeteci voi quello che più vi piace; dopo la riunione a Jekyll Island nel 1910 ai sette imprenditori interessati alla creazione della fed rimangono 3 ostacoli che “casualmente” o se preferite sfortunatamente si ritrovarono tutti e tre come passeggeri del viaggio inaugurale di una nave che apparteneva, tramite un sua controllata, la White Star Line, a J.P. Morgan (finanziatore dell’ International Mercantile Marine Company), il quale, data l’importanza e la pubblicità fatta al varo di questa imponente nave, doveva essere lui stesso ospite VIP e passeggero ma che, guarda la fortuna, a causa di un improvviso impegno di lavoro dovette rinunciare a partecipare al viaggio. Dunque il famoso Iceberg diede la possibilità al progetto di trasformarsi in realtà e così nel Dicembre del 1913 il Sistema della Federal Reserve venne istituito dal governo degli Stati Uniti come sistema monetario ufficiale.
A questo punto andiamo ad analizzare quella che è la crisi del 1929 (ovvero la grande Depressione del ’29) il momento di depressione dell’economia degli Stati Uniti più famoso ed analizzato (ma non l’unico) un momento che tutti conosciamo come una crisi a livello economico che sembra normale inizialmente ma che mano a mano cresce sempre più fino a diventare un disastro economico enorme, su cui il premio Nobel per l’economia Milton Friedman dirà che: << questa crisi fu causata proprio dalle banche e dal fatto che la federal reserve vedendo questa arrivare ha volutamente non agito e non mosso un dito proprio per ingigantire questa crisi>>. Qualche anno dopo, durante un evento per festeggiare il compleanno di Friedman, l’ex Presidente della FED Ben Bernanke disse: ” Vorrei dire una cosa a Milton e Anna: avevate ragione, lo abbiamo fatto è stata colpa nostra. Ci dispiace molto, ma grazie a voi non lo rifaremo”. Di cosa è stata accusata quindi la FED da alcuni degli economisti più importanti degli ultimi decenni? Beh il fatto portato alla luce è quello per cui, in questo caso la federal reserve rimase ferma a guardare il mercato per ben 4 anni prima di intervenire; finalmente nel 1933 quindi quattro anni dopo, la fed decide di intervenire e come la salvi un’economia in crisi? stampando denaro, e come stampi una montagna di denaro in un mondo dove c’è ancora un sistema basato sull’oro? sequestrandolo agli americani. Infatti nel 1933 viene promulgato l’ordine esecutivo 6102 con l’imperativa ad ogni singolo cittadino americano di vendere o svendere il proprio oro alla fed a circa 20 dollari l’oncia, meno di un dollaro al grammo e se non lo vendevi alla fed potevi scontare dieci anni di carcere o pagare l’equivalente di circa 200.000 dollari odierni. Quindi la fed rimase prima ferma per 4 anni, nel momento di crisi più profonda degli stati uniti, e poi arriva a salvare tutti sequestrando l’oro degli americani rubandolo per pochissimi centesimi minacciando la popolazione di finire in carcere; così di fatto dopo aver acquisito con la forza il monopolio dell’oro , il governo degli stati uniti, tramite la fed, può stampare quante banconote vuole e quindi finalmente sopperire al bisogno di liquidità che secondo le Loro stime necessitava il sistema economico (è il solito trucco, usato ancora ai nostri giorni del “crea il problema e poi presenta la TUA soluzione”); tutto bene, per modo di dire, fino al giugno del 1963, la fed ha ancora tutto il suo potere di stampa di denaro grazie al monopolio dell’oro che ha estorto ai cittadini americani ma arriva uno dei più famosi presidenti degli stati uniti che prova a contrastare il monopolio sul dollaro da parte della fed ovvero John Fitzgerald Kennedy che nel giugno del 1963 firma l’ordine esecutivo 11110 tramite il quale dava al Ministero del Tesoro il potere di: <<emettere certificati d’argento contro ogni lingotto d’argento, argento o dollari standard argentei del tesoro non tenuti per il rimborso di certificati d’argento preesistenti, di prescrivere la denominazione di questi certificati d’argento e di coniare gli “standard silver dollars” e le valute complementari rimborsabili in argento» in poche parole le banconote erano convertibili in argento, tutto questo in mano allo stato e non ad una banca privata. Beh che fine ha fatto Kennedy lo sappiamo, SI?! Qualche anno dopo l’improvvisa decisione del Presidente Richard Nixon promulgata il 15 Agosto del 1971 segnò la fine del sistema monetario internazionale del dopoguerra, creato nella conferenza di Bretton Woods, stoppando di fatto il Gold Standard, dunque il Dollaro non era più convertibile in oro.
Ora vorrei porre l’attenzione su alcune cose e su come ancora esistano persone che sostengono che enti centrali come la banca europea (BCE) siano enti sicuri, andiamo dunque ad analizzare la banca centrale europea che non abbiamo trattato fino ad ora e, partiamo per esempio dai suoi dirigenti, ma prima di elencare i nomi dobbiamo introdurre un argomento estremamente interessante ovvero il gruppo Bildelberg che, per chi non lo sapesse, il club Bildelberg è un club esclusivo che si riunisce ogni anno e all’interno di esso ci sono circa 120 degli uomini più potenti al mondo, dai banchieri, politici dagli industriali alle grandi personalità famose, e discutono a porte chiuse di cose che, come dice un articolo del Times del 1971:” pianificano eventi che poi risulteranno come casuali“. Questo gruppo è stato fondato dal celeberrimo David Rockefeller, il quale in un’intervista, riportata anche sulla sua e biografia, afferma: ” la sovranità sovranazionale di un elite del mondo intellettuale dei banchieri è preferibile rispetto a quella dell’autodeterminazione nazionale e personale praticata nei secoli passati” e inoltre afferma che: ” alcuni credono che facciamo parte di una cabala segreta che manovra contro gli interessi degli stati uniti, che cospira con altri nel mondo per costruire un nuovo mondo, e se questa è l’accusa mi dichiaro colpevole e sono orgoglioso di esserlo”. Quindi che cos’è questo club? E’ semplicemente un luogo in cui persone estremamente potenti nel mondo finanziario/politico si riuniscono e discutono di argomenti a porte chiuse in maniera segreta, infatti non ci sono video delle discussioni interne, e quel poco che sappiamo, come ad esempio le liste dei partecipanti le dobbiamo a dei leaks di Wikileaks; ora che abbiamo presentato questo fantastico club andiamo ad elencare i legami con i governatori della banca centrale europea, iniziamo dal 2003 che è quando l’euro è diventato ufficiale e dal 2003 fino al 2011 abbiamo come capo della banca centrale europea Jean-Claude Trichet membro della lobby belga Bruges, del gruppo dei 30 e del Bildelberg; nel 2011 Trichet passa la palla a Mario Draghi ex dirigente di Goldman Sachs, membro del gruppo dei 30 e governatore della Banca d’Italia. Già questo dimostra che le persone di potere si alternano sempre tra di loro infatti il nostro marione partecipa al Bildelberg del 2009 e nel 2011 viene nominato governatore della banca centrale europea, nel 2019 passerà la palla a Christine Lagarde che aveva partecipato con lui al Bildelberg del 2009 e che nel 2011 diventerà presidente del fondo monetario internazionale, poi nel 2019 governatrice della banca centrale europea etc….. Abbiamo dunque visto che la banca centrale europea è governata da un certo tipo specifico di persone e voi pensate veramente che queste lavorino per il bene del mondo? In questa fase economica mondiale basata sul FIAT Standard, tutti gli stati per stampare moneta devono fare debiti con le banche centrali e quindi la banca centrale europea (BCE) ha in mano le redini dei debiti pubblici di tutti gli stati che hanno aderito alla Comunità Europea, così come la FED di quelli americani, che ricordiamolo sono 50 stati. Questo perchè nel FIAT Standard non solo le banche centrali possono stampare denaro poichè possono farlo anche le banche commerciali e il metodo usato è quello della riserva frazionaria (secondo wikipedia in Europa la riserva frazionaria, secondo il regolamento Basilea1 del 1988 era dal 2% ma dal 18 Gennaio 2012 è stato portato all’ 1%). L’ 1% ci pensate all’assurdità di questo valore, totalmente in barba a ciò che viene sbandierato per cui per tenere tranquilla la gente viene fatto credere che i soldi depositati, al di sotto dei 100.000 euro, sono protetti, ma provate ad immaginare se domani arriva una notizia improvvisa di un crack della vostra banca…., cosa succede? la storia lo ha insegnato, scatta la corsa allo sportello (bank run), e se la banca tiene solo l’ 1% di deposito come può ridare a tuttti i richiedenti i soldi? non può. Dunque la banca verrebbe messa in controllo amministrativo, i patrimoni bloccati, conti bloccati ect etc etc…. Non ho volutamente usato il termine “i vostri soldi” perchè, come già detto in un precedente articolo, la maggior parte di noi usa la banca su un principio di FIDUCIA per cui in pochi sanno che :
[[ “Articolo 1834 Codice Civile (R.D. 16 marzo 1942, n. 262) [Aggiornato al 01/12/2021] Depositi di danaro “Nei depositi di una somma di danaro presso una banca, questa ne acquista la proprietà ed è obbligata a restituirla nella stessa specie monetaria, alla scadenza del termine convenuto ovvero a richiesta del depositante, con l’osservanza del periodo di preavviso stabilito dalle parti o dagli usi“. ]]
Quindi i soldi sono i tuoi fino a che non li depositi in banca o quando li ritiri in contante (chiedendo se cortesemente te li fanno prendere poichè anche sul ritiro cospicuo dei propri soldi esistono ulteriori limitazioni relativi alla quantità), in tutte le altre fasi il tuo denaro non è tuo ma è la banca a gestirlo come meglio crede e come più le fa comodo. SAPPILO !!”
Prelevamenti denaro contante dal conto corrente soglie e limiti: “Da gennaio 2023 il limite per l’utilizzo di denaro contante è salito a 5.000 euro. Il limite di prelievo contante dal conto corrente, invece, anche per importi frazionati, nell’arco di un mese è fissato alla soglia di 10 mila euro. Superata la soglia è prevista la segnalazione alla UIF da parte dell’istituto bancario. (3 gen 2023)”.
Torniamo quindi al discorso della riserva frazionaria e sul fatto che anche le banche commerciali possono stampare/creare denaro, e come avviene tutto ciò ?? è facile le banche commerciali creano moneta ogni volta che concedono un “nuovo” prestito sfruttando quell’ 1% della riserva frazionaria; la moneta viene distrutta/cancellata dal registro contabile ogni volta che il debito viene estinto (nel nostro caso potrebbe essere nel momento in cui io ripago tutto il prestito per l’acquisto della casa alla mia banca).
Sia la Banca Centrale Europea (BCE) sia le BCN dei paesi partecipanti all’area dell’euro hanno titolo legale a emettere banconote in euro.
Quindi sì le banche centrali stampano moneta e vi rubano potere d’acquisto ma anche le banche commerciali stampano moneta e vi rubano potere d’acquisto insomma il cittadino comune utilizzatore di moneta fiat è abbastanza fregato. Con il potere di creare denaro dal nulla, cosa succede quando se ne stampa troppo? non è un mistero infatti che quando si stampa troppa moneta sale l’inflazione (sembra che solo la Lagarde non ne fosse al corrente) e le banche centrali come la FED alzano i tassi di interesse; e perché alzare i tassi di interesse fa diminuire l’inflazione? semplicemente perché all’aumentare dei tassi prendere un mutuo costa di più, così si hanno due reazioni: 1) la gente spende meno perché vuole risparmiare di conseguenza, 2) non volendo contrarre nuovi debiti chiede meno prestiti e l’economia rallenta (torniamo al crea il problema e poi dai la TUA soluzione).
RIFLESSIONE: abbiamo detto che tutti stampano denaro, le banche centrali stampano denaro, le banche commerciali stampano denaro e il denaro si crea facendo debito; questo vuol dire che per assurdo tutto il denaro che voi vedete in circolazione, tutta la moneta costituisce un debito uguale contrario, quindi se, ad esempio, esistono un miliardo di euro stampati esiste un equivalente debito da un miliardo di euro, quindi lo stato per stampare moneta fa un debito con la banca centrale e se esistono un miliardo di euro esiste un miliardo di debito ma in questa equazione manca una cosa fondamentale che sbilancia il tutto ovvero che se tutta la moneta creata è il 100% il debito in realtà è 101% perché c’è un interesse, quell’uno per cento ovvero quell’interesse non è mai stato stampato non è ricchezza, non è mai stata creata non esiste in un’ottica globale quindi il debito non si può estinguere perché alla creazione di 100 di moneta corrisponde un 101 di debito e per pagare 101 non esiste 101 di moneta l’unico modo per pagare 101 sarebbe stampare quell’uno di moneta che manca ma stampandolo si crea altro interesse, di conseguenza il debito mondiale che al momento esiste non è pagabile perché non esiste una massa monetaria equivalente a pagare questo debito; semplificando il concetto alla moneta FIAT a debito è questo: se io ho 1000 euro e voi mi chiedete un prestito di 1000 e usiamo come moneta dei foglietti di carta con un mio sigillo, che ho soltanto io, voi mi chiedete un debito di 1000 foglietti e io vi dico va bene te li presto ma tu mi dai l’1% di interesse in un anno, succede che voi dopo un anno mi dovrete restituire 1010 foglietti con sigillo che però posso creare solo io, ma se ne esistono solo 1000 voi non potrete darmene indietro 1010 perché quel 10 mancanti, di interesse, non esiste non c’è non esiste fisicamente e la nostra economia mondiale funziona esattamente così, creiamo moneta creiamo un miliardo di euro ne dobbiamo restituire un miliardo e un milione, quel milione di interessi non esiste non c’è e quindi il debito mondiale non è ripagabile e anzi, in un sistema basato sull’oro con un Gold standard se noi dessimo indietro una banconota alla banca centrale essa ce la cambierebbe in oro, ma la moneta come la banconota attuale da 50 euro che cosa ha come sottostante? non oro ma solo debito, questo vuol dire che addirittura se tutto il debito del mondo fosse istantaneamente pagato in una sola volta le vostre banconote non avrebbero più alcun valore perché le vostre banconote sono una rappresentazione di debito che il vostro stato ha con la banca centrale se questo debito venisse ripagato la vostra banconota avrebbe valore monetario zero.
Le valute Digitali delle banche centrali (CBDC)
Bitcoin ha compiuto da pochi giorni i suoi primi 15 anni e se dovessimo tornare indietro di qualche anno potremmo vedere come nel brevissimo periodo il tono delle banche centrali nei confronti di Bitcoin è cambiato radicalmente. Ancora nel 2018, qualunque banchiere centrale lo avrebbe liquidato sommariamente facendo riferimento alla bolla dei tulipani nella Amsterdam del XVII secolo, ma già dal 2021, il timore dell’espansione di Bitcoin (non del settore cripto in generale) li sta spingendo verso la spasmodica ricerca di attuazione delle “valute digitali”, le CBDC.
I banchieri centrali vogliono presentarci le CBDC solo come un progresso tecnologico in grado di consentire pagamenti digitali più rapidi e sicuri. Non parlano invece del loro potenziale trasformativo a fini di sorveglianza, clientelismo politico e pianificazione economica centralizzata. Le CBDC darebbero alle banche centrali la possibilità di sorvegliare in tempo reale i conti correnti/portafogli e le spese di tutti i cittadini, permetterebbero ai governi di tassare i propri cittadini agendo direttamente sui loro portafogli con prelievi, blocco dei conti (vedi le manifestazini dei camionisti in Canada). Ma il pericolo maggiore delle CBDC è quello per cui questa moneta digitale è programmabile, questo significa che in base alle regole che man mano vengono emanate ed applicate dalla banca centrale e dalla comunità europea possono essere imposte in ogni momento restrizioni sul loro uso, ad esempio: hai un’auto a benzina o diesel, la UE dice che devi avere una macchina elettrica, se non la acquisti possono intervenire sul tuo portafogli e bloccarlo perchè hai contravvenuto ad una direttiva; non hai fatto la 12esima dose ? conto bloccato fino a quando dai dati del SSN (servizio sanitario nazionale) non saranno aggiornati riportando che hai fatto anche la 12esima dose…. e via così; inoltre il fatto che sia programmabile fa si che il denaro digitale possa avere una scadenza di utilizzo rendendo impossibile accumularlo come forma di ”risparmio”, la scusa potrebbe essere che c’è bisogno che tu spenda per far girare l’economia, mentre se accumuli sei un cattivo cittadino. VI BASTA ???
Conclusione
Esiste un modo per poter gestire il proprio denaro nel prossimo futuro? SI, Bitcoin ma bisogna uscire dalla pigrizia del credere che vada tutto bene, dare fiducia con troppa facilità, in particolare alle istituzioni, e decidersi a studiare perchè : “solo il sapere rende liberi, è l’ignoranza che rende prigionieri. (Socrate)“.
OK, con questa dichiarazione si capirà che sono un sistemista di vecchia scuola, per l’appunto ho iniziato ad occuparmi di sistemi HPC/Cluster nei primi anni 2000 ed ho realizzato il mio primo importante sistema Cluste HPC nel lontano 2004, da quel momento ho lavorato nello stesso ambito per grosse aziende in ambiti bancario, assicurativo, editoria, pubblica amministrazione etc…… ; ho potuto dunque analizzare per esperienza diretta che quello che legava tutti questi ambienti, che si stavano aprendo al mondo dell’offerta di servizi web online per i loro clienti (outsourcing), era la “ovvia” gestione in loco (on premise) dei dati aziendali, nonostante questo comportasse un forte investimento in hardware/network e sviluppo del software. Tutto ciò permetteva di tenere sotto controllo l’andamento dei progetti perchè per far funzionare tutti quegli avanzamenti tecnologici serviva far crescere anche il livello di preparazione tecnologica del proprio personale IT, seppur con le dovute integrazioni esterne di consulenti ad hoc, atti a portare uno slancio alla realizzazione finale del prodotto.
Dunque in un’azienda servivano un tot persone skillate in vari ambiti che procedessero di pari passo nel far avanzare il progetto fungendo anche da beta tester per i colleghi degli altri team, team solitamente suddivisi in:
Sistemisti
Database Administrator
Networking
Sviluppo (developer)
Cyber Security
Ogni gruppo testava se stesso e faceva da tester per gli altri così da arrivare , step by step, ai vari rilasci di pre-produzione e produzione, diminuendo, a mio avviso, di gran lunga il Bug da errore umano.
Credo che tutto ciò abbia funzionato piuttosto bene, in una specie di “status quo” fino all’arrivo della crisi del 2008 ed in particolare degli strascichi sui budget i cui effetti si sono visti negli anni subito successivi, nel frattempo il maggior sviluppo di piattaforme Cloud proposte dai Big come Gloogle Cloud ed Amazon AWS (in particolare) hanno portato alla decisione sempre più massiccia dei Manager di esternalizzare tutti i processi verso queste piattaforme per massimizzare gli sforzi nello sviluppo (programmazione) dei servizi eliminando dai budget le spese hardware, quelle per le location da dedicare alla ridondanza dei dati ed ai sistemi di backup integrati. Tutto questo ora era possibile pagarlo in un forfait di servizi on chain offerti dalle piattaforme Web-Cloud che hanno invaso il campo di gioco con acronimi di ogni genere, tra cui i primi furono le PaaS, SaaS, IaaS, CaaS, DaaS etc…. (solo la fantasia li può fermare) tagliando così anche le competenze dirette dei team poichè adesso le piattaforme web, la loro gestione, il mantenimento software, gli aggiornamenti, i backup, le problematiche di rete, i DNS, le connessioni VPN, la sicurezza e quant’altro potevano essere preoccupazione ed appannaggio di altri.
Tutto ciò per me ha solo impoverito il nucleo di esperti IT, smembrando i suddetti team e generando nuovi mostri poichè le aziende diventarono prede di “metodologie” di lavoro in stile Silicon Valley (ma ehi la verità è che funzionano solo in Silicon Valley) come la Agile, è da li sono partiti inglesismi lavorativi come lo “stand up meeting”, il “parking lot”, arrivando oggi all’uso di Framework per supportare l’Agile come lo “Scrum” che ha introdotto la figura dello “scrum master” e via di questo passo. Ma quello che si è potuto vedere è che mentre prima i Team IT aziendali necessitavano di specifiche competenze , adesso posson bastare come capo progetto uno sviluppatore Senior con conoscenze da sistemista o un sistemista con conoscenze di programmazione per mandare avantiil 70% dei progetti perchè il resto lo prepara la piattaforma Cloud che ti aiuta a gestirlo con comodi tool grafici Plug ‘n Play e se qualcosa non funziona c’è il blog/tutorial o il call center…….. semplice giusto?
Certo qualcuno potrà giustamente dire che così è tutto più mirato, perchè no più comodo, e le aziende possono essere più verticali sullo sviluppo e sul risultato finale, FORSE, ma se devo cedere capacità cognitive, conoscenza dei sistemi e competenze di problem solving solo perchè è più pratico allora forse sto sbagliando mestiere. Non parliamo poi del nuovo arrivato, la A.I. , con ChatGPT e compagnia bella… quella unita ai movimenti No-Code, non fanno ben sperare per una futura esistenza delle ultime figure rimaste (gli sviluppatori) che credo si dovranno preparare a periodi di transizione poco rosei.
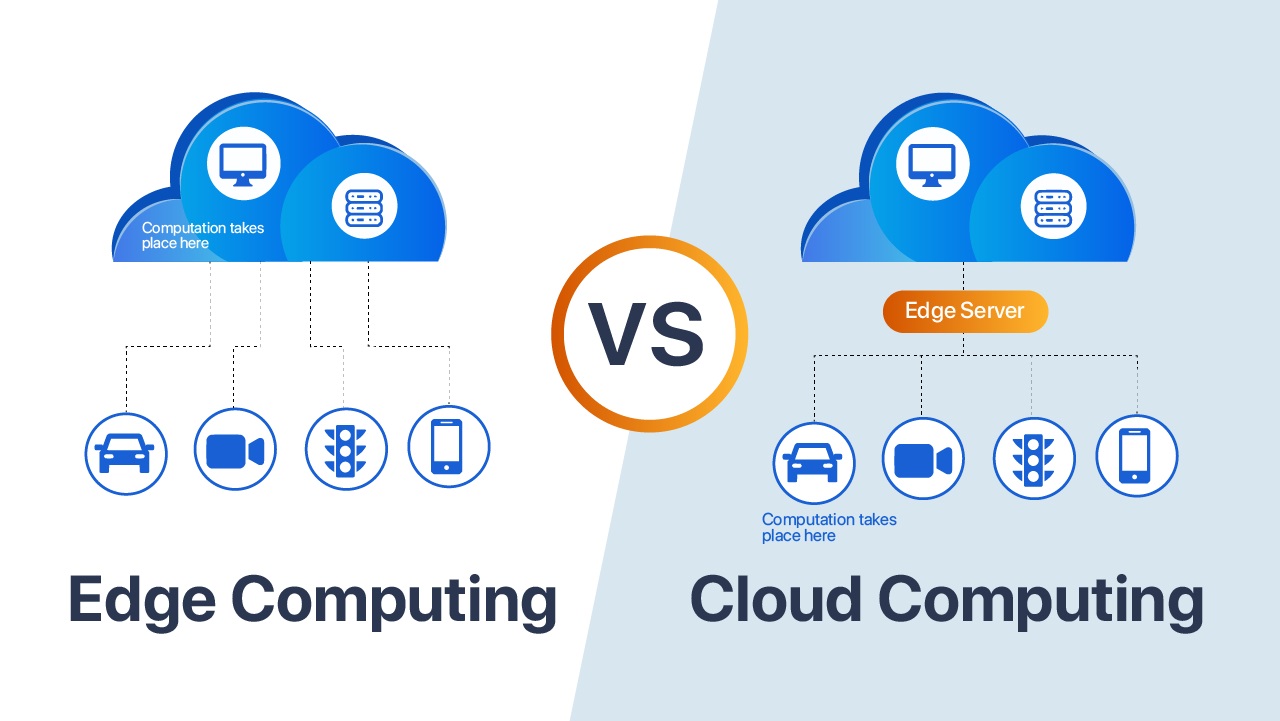
Il futuro non lo si può arrestare, arriva comunque dunque è giusto imparare a conoscerlo per capire come e quali cose sono vantaggiose da utilizzare, e che cosa invece determinerà la perdita di competenze apprese con fatica, studio ed esperienza lavorativa. Si potrebbe fare qualcosa per riprendere un minimo il controllo? Credo di SI, innanzitutto diminuendo la dipendenza dai sistemi Cloud esterni e tornando a volersi sporcare le mani in casa, quindi spazio alla rinascita dei data center aziendali costruiti su misura dei progetti reali ed implementati dalle persone che li gestiranno e li faranno crescere e scalare nel tempo, quindi riprendiamoci il controllo dei dati, in primis, e dei sistemi con loro, più sistemi on premise e Edge Computing e meno esternalizzazione con il Cloud Computing.
Vantaggi dell’ Edge Computing
L’edge computing è preferibile al cloud computing in molte situazioni e per diversi motivi chiave, tra cui sicurezza, controllo dei dati e velocità di elaborazione dei dati.
Sicurezza: Nell’edge computing, i dati sono elaborati più vicino alla loro origine, riducendo il rischio di esposizione a minacce esterne. Questo approccio migliora la sicurezza dei dati sensibili.
Controllo dei Dati: Con l’edge computing, le organizzazioni mantengono un maggiore controllo sui propri dati. I dati rimangono locali o in prossimità dei dispositivi, consentendo un controllo diretto sull’accesso e sulla gestione.
Velocità nell’Elaborazione dei Dati: Poiché i dati vengono elaborati localmente nell’edge computing, la latenza è ridotta al minimo. Questo è fondamentale per applicazioni in tempo reale, come il monitoraggio industriale o i molti sistemi di monitoraggio delle città moderne (IoT), dove ogni millisecondo conta.
Risparmio di Banda: Elaborare i dati in loco riduce la necessità di trasferire grandi quantità di dati in cloud, risparmiando banda e costi associati.
Affidabilità: L’edge computing migliora l’affidabilità delle applicazioni. In caso di interruzione della connettività cloud, i dispositivi edge possono continuare a funzionare autonomamente.
Scalabilità: L’edge computing è altamente scalabile. È possibile aggiungere dispositivi edge in modo modulare per gestire carichi di lavoro crescenti.
Privacy: Per alcune applicazioni, come il monitoraggio della salute in tempo reale, la privacy dei dati è essenziale. L’edge computing mantiene i dati locali, riducendo le preoccupazioni sulla privacy.
In sintesi, l’edge computing è una soluzione vantaggiosa per applicazioni che richiedono velocità, sicurezza e controllo dei dati. Tuttavia, è importante notare che non esclude completamente il cloud computing, ma piuttosto lo integra in un modello ibrido per massimizzare i benefici.
Svantaggi dell’uso del Cloud Computing
Aumento della Latenza: Nel Cloud, i dati devono viaggiare attraverso una rete molto estesa fino ai server remoti, causando ritardi (latenza) nell’elaborazione. Nel modello di Edge Computing, la distribuzione delle risorse di elaborazione avviene all’edge della rete, vicino ai dispositivi o ai sensori. Ciò elimina la necessità di trasmettere dati su lunghe distanze ai server remoti del Cloud, riducendo significativamente la latenza. Questa bassa latenza è essenziale per applicazioni in tempo reale come il controllo industriale, la guida autonoma e la realtà virtuale, migliorando notevolmente l’efficienza e la reattività dei sistemi.
Dipendenza dalla Connessione Internet: Il Cloud richiede una connessione Internet costante, mentre l’Edge Computing funziona anche offline, garantendo continuità operativa.
Controllo sull’Infrastruttura: Nel Cloud, hai meno controllo sull’infrastruttura sottostante, poiché è gestita dal provider. Con l’Edge Computing, hai maggiore controllo su hardware e sul software.
Sicurezza e Privacy: Il Cloud può presentare rischi di sicurezza dovuti alla memorizzazione dei dati su server remoti. L’Edge Computing può offrire un maggiore controllo sulla sicurezza, poiché i dati rimangono locali.
Costi Operativi: Il mantenimento di server remoti nel Cloud può comportare costi operativi elevati, mentre l’Edge Computing può essere più economico in particolare per piccole implementazioni locali.
Complessità della Gestione: La gestione di ambienti Cloud complessi può richiedere competenze specializzate, mentre l’Edge Computing può essere più semplice da gestire localmente.
Certo tutto questo può essere solo un parere soggettivo determinato dalle mie personali esperienze lavorative, per altre persone potrà essere l’esatto contrario, rimango comunque dell’avviso che ciò di cui ho parlato descrive, in un paragone calzante, le stesse problematiche che il mondo sta affrontando per l’eccessiva deindustrializzazione dell’occidente che ha deciso decenni addietro di esternalizzare i processi produttivi sull’onda del concetto di “globalizzazione”, per il quale si è arrivati oggi ad essere dipendenti dei nostri fornitori (vedi la Cina solo per fare l’esempio più lampante) senza i quali non potremmo assemblare un PC o un telefonino, produrre abbastanza energia elettrica etc….
Alla fine un’azienda non è così diversa da uno Stato, lo Stato per essere definibile come tale deve avere un popolo che lo contraddistingue ed un territorio su cui esercita la sua sovranità; un’azienda necessità di proprio personale che apporta lavoro ed intelletto, che crea e genera idee da cui scaturiscono know-how e magari anche brevetti e deve essere la proprietaria di tutto ciò che produce e/o trasforma, altrimenti per entrambi i casi parliamo solo di “Colonie”.
Per chi ancora non conosce il progetto IPFS (creato all’interno del MIT di Boston), posso cominciare dando la definizione riportata sulla pagina Wikipedia, ossia che: L’InterPlanetary File System (IPFS) è un protocollo di comunicazione e una rete peer-to-peer per l’archiviazione e la condivisione di dati in un file system distribuito.
IPFS basa il suo funzionamento sull’utilizzo di molteplici tecnologie, racchiudendo in se le più moderne idee alla base di precedenti sistemi peer-to-peer, inclusi DHT, BitTorrent, Git e SFS.
Bene, dopo questa introduzione dobbiamo capire cosa si può già realmente fare con IPFS, poichè essendo un progetto in forte sviluppo, sono già parecchi gli usi pratici su cui potremo inserire IPFS in un nostro progetto.
Ma quella definizione di “Sistema Interplanetario per la gestione dei dati” potrebbe forse farvi comprendere la vicinanza di questo progetto con la blockchain. Infatti quando è nata la tecnologia della Blockchain, il Bitcoin aveva lo scopo di far usare la blockchain per espandere la libertà finanziaria a tutti coloro che avrebbero usato quel sistema. IPFS vuole portare ulteriormente avanti il concetto da cui è nata la blockchain, non a caso, per gli sviluppatori del progetto la stessa blockchain non dovrebbe essere vista legata solamente alle transazioni di denaro (immagine che attualmente è stata appiccicata a questa fantastica tecnologia ), ma bensì dovrebbe rappresentare la nuova infrastruttura di Internet.
In pratica, Internet, così come lo conosciamo oggi, non dovrà più essere il sistema a cui noi semplicemente accediamo, e di cui qualcun’altro possiede l’infrastruttura.
Proviamo a fare un esempio che possa essere chiaro per tutti:
Oggi quando cerchiamo Facebook sul motore di Google, stiamo compiendo le seguenti azioni
Chiediamo a Google di cercare Facebook, per poi
Chiedere a Facebook di mostrarci che cosa fanno i nostri contatti
..tutto ciò senza considerare tutti i passaggi intermedi che ci servono per arrivare su Google e successivamente arrivare a Facebook, ad iniziare dalla prima "request" che viene fatta dal nostro device al nostro gestore di connessione, che sia il provider che ci fornisce la linea di casa o l’operatore telefonico che ci fornisce la rete per navigare.
Passaggi nei quali lasciamo in rete un sacco di tracce, dal nostro indirizzo IP, il nostro indirizzo MAC(ossia l’identificatore unico e univoco del nostro dispositivo connesso in rete), la localizzazione geografica della nostra posizione in tempo reale, la versione di Browser che stiamo utilizzando, fino alla stringa di ricerca che vogliamo venga esaudita. Insomma un bel pò di dati per una semplice ricerca.
Consideriamo adesso che tutte le aziende attraverso cui passano i nostri dati di navigazione, possono leggere e dunque sfruttare tutte queste informazioni per capire come ci comportiamo in rete, cosa siamo soliti cercare, se siamo appassionati di viaggi o di informatica, se abbiamo preferenze verso certi prodotti piuttosto che altri, e molto altro ancora, una vera e propria profilazione.
Ma una profilazione non serve solo come agglomerato di dettagli e specifiche di un’ utente, vendute agli inserzionisti per creare una pubblicità su misura per ogni singolo internauta. Una profilazione di questo tipo identifica una specifica persona meglio delle sedute dallo psicanalista, e non serve usare il concetto di coloro che sono soliti dire: "ma io non ho nulla da nascondere", in quanto il concetto di Privacy non nasce per difendere coloro che hanno qualcosa da nascondere. Immaginate di diventare dei VIP e che improvvisamente stuoli di giornalisti e paparazzi si piazzino davanti a casa vostra, cercando di rubare un momento qualunque della vostra vita, fotografandovi ovunque voi siate……, credo che invochereste il diritto di privacy immediatamente, non perchè abbiate qualcosa da nascondere, ma perchè avete una vostra vita da vivere; allora immaginiamo questi "scrutatori" della vostra vita, come costantemente parcheggiati nel vialetto davanti alla vostra stradina per navigare in Internet. Appena vi collegate, per un qualunque motivo, loro sono già li tutti pronti a scattare foto di ogni attimo della vostra navigazione, che sia per lavoro o per svago.
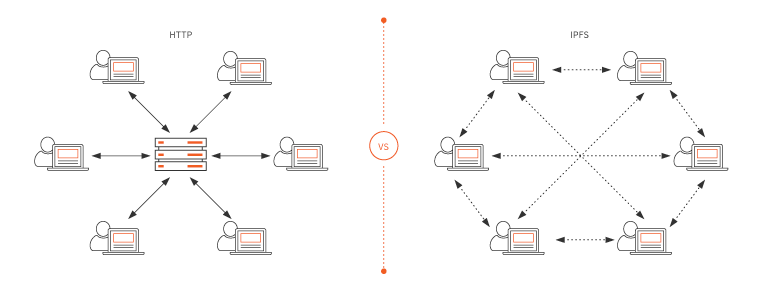
Adesso immaginiamo come potrebbe essere la stessa esperienza se non ci fosse bisogno di "Internet, per accedere ad Internet", questo è quello che stanno cercando di realizzare con IPFS, costruendo un protocollo di navigazione che sostituisca HTTP/S, ormai vecchio, accroccato e che non riesce più a stare al passo con la costante crescita delle innovazioni del WEB. Tenendo anche presente che l’http/s è un protocollo di livello 4, mentre nella pila (ISO/OSI) dei protocolli di rete ci sono ben 7 livelli.
IPFS vuole dunque cambiare il protocollo standard da https:// a ipfs:// , che può sembrare una cosa insignificante, invece tutto questo cambia moltissimo l’uso della rete per ogni utente, perchè con IPFS quando richiediamo un’informazione in rete , non la stiamo più chiedendo ad un insieme di server, sparsi chissà dove nel mondo, e di proprietà di una Big Corporation, ma lo stiamo chiedendo a qualcuno che si trova vicino a noi e che condivide quella informazione, nello spirito dei sistemi peer-to-peer.
Oggi il web è fondamentalmente inefficiente e costoso perché internet costa in ogni suo singolo aspetto, dalla connessione, alle infrastrutture per i servizi che si appoggiano, tutti, troppo, alle infrastrutture GAFA (Google, Amazon, Facebook, Microsoft), di conseguenza, non è possibile immaginare l’attuale Internet come il luogo che preserverà la storia umana.
I vantaggi che si potrebbero trarre dall’utilizzo di IPFS sarebbero molteplici, ad esempio:
• download più veloci ed efficienti: mentre HTTP può scaricare una risorsa da un solo computer alla volta, IPFS pu`o recuperare parti diverse di un file da molteplici computer contemporaneamente;
• un web più robusto: l’architettura di IPFS elimina i server centrali che rappresentano un single point of failure permettendo la creazione di un Web “permanente”. IPFS crea una rete resiliente dove ogni risorsa è sempre disponibile grazie al mirroring dei dati su più nodi;
• resistenza alla censura: mentre può essere molto semplice per un governo bloccare l’accesso a un determinato sito internet ospitato presso un server centralizzato, IPFS crea un Web immune alla censura.
Wikipedia è stato uno dei primi progetti ad essere stato “portato” su IPFS con un progetto che si chiama Distributed Wikipedia.
Dunque come iniziato ad accennare all’inizio dell’articolo, <u>IPFS è un sistema distribuito per l’archiviazione e l’accesso a file, siti Web, applicazioni e dati</u>.
Questo, in soldoni, significa che potrai archiviare qualsiasi tipo di dato/file in IPFS e, dopo averli archiviati, IPFS fornirà un hash che inizia con Qm. Si potrà quindi accedere ai dati usando quell’hash.
HASH
Che cosa sono e quale scopo hanno gli hash ?
L’hash in termini tecnici è noto come Identificatore di contenuto (CID) in IPFS. Il CID è sostanzialmente un’etichetta utilizzata per indicare il contenuto in IPFS, ma non indica dove è archiviato il contenuto. L’hash crittografico del contenuto viene quindi utilizzato per generare CID. L’hash corrisponde a un multihash di caratteri che inizierà con “Qm”. Le lettere “Qm” definiscono l’algoritmo (SHA-256) e la lunghezza (byte 32) utilizzati da IPFS.
Gli hash sono funzioni che accettano input arbitrari e restituiscono un valore di lunghezza fissa. Essi possono essere rappresentati in diverse basi (base2, base16, base32, ecc…).
Caratteristiche degli hash crittografici:
Deterministico
Non correlato
Unico
Senso unico
L’utilizzo dell’hash come chiave per l’identificazione dei file ha inoltre il vantaggio di garantirne l’integrità, poichè, così facendo, il nodo che ha richiesto una risorsa, per assicurarsi che il file ottenuto sia effettivamente quello richiesto e che non abbia subito alcuna alterazione, non dovrà far altro che ricalcolarne l’hash e verificare che questo corrisponda con quello che aveva inizialmente richiesto. Oltre ad aggiungere questa misura di sicurezza gratuitamente, la scelta di utilizzare l’hash come chiave porta un secondo vantaggio, ovvero la deduplicazione dei file: ogni volta che un utente pubblica un nuovo file su IPFS, la rete verifica attraverso il suo hash se questo è già presente, evitando automaticamente che ne vengano mantenute molteplici copie qualora più utenti caricassero la medesima risorsa.
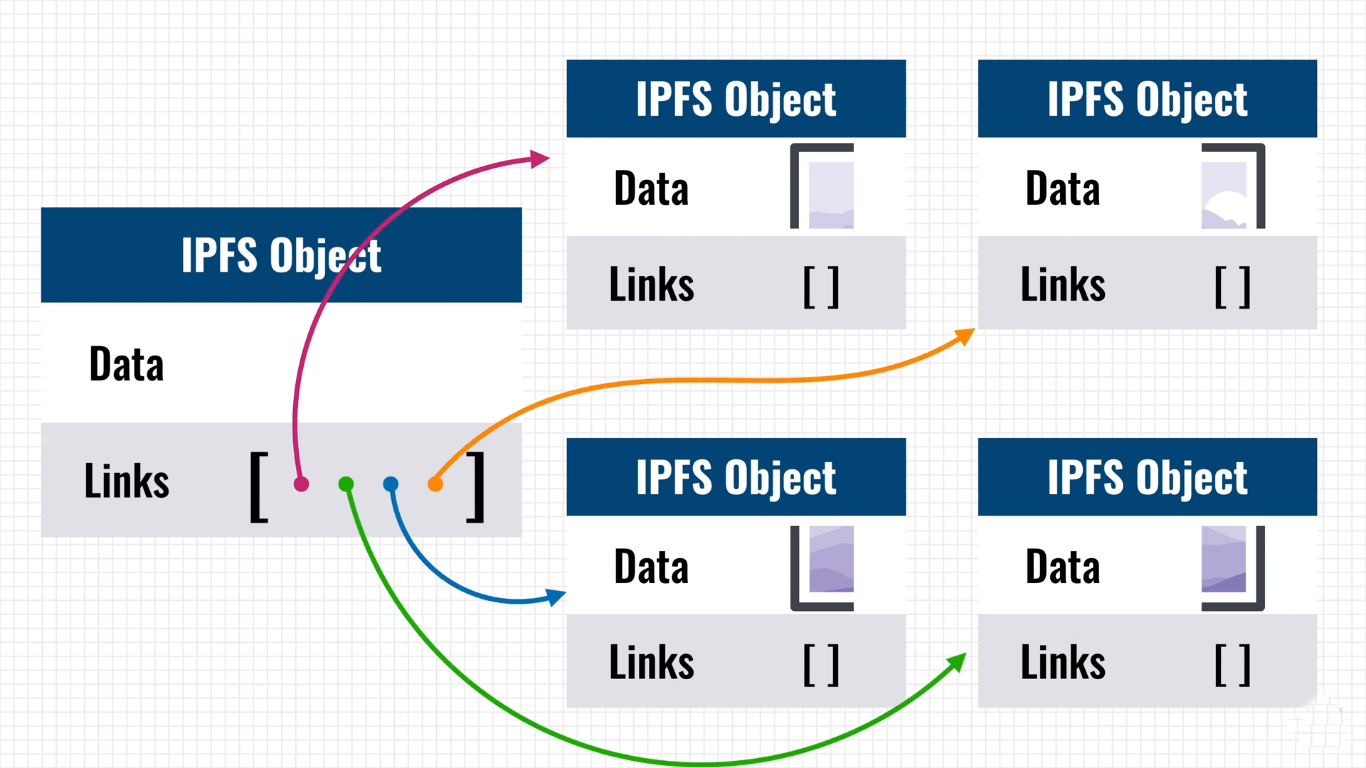
Dal momento che IPFS utilizza l’indirizzamento basato sul contenuto, i file memorizzati su di esso non possono più essere modificati, infatti qualunque aggiornamento al file produrrebbe anche una modifica dell’hash che lo identifica. Per questa ragione IPFS, esattamente come Git, supporta il versioning dei file. Ogni volta che il contenuto di un file viene aggiornato, IPFS crea un oggetto chiamato commit che rappresenta un particolare snapshot nella cronologia delle versioni di un determinato IPFS object. Ogni commit contiene un riferimento al commit precedente e un link alla specifica versione dell’IPFS object (vedi immagine). IPFS tiene traccia in questo modo dell’ultima versione del file e di tutte le versioni precedenti.
SALVARE I DATI
pinning
Ora, una volta spiegato cosa c’è alla base del progetto IPFS, dobbiamo chiarire alcuni punti importanti. IPFS usa lo slogan per cui ciò che SALVI sul sistema rimarrà li per sempre….. SI & NO. La precisazione va ben fatta perchè, facciamo un esempio: Qualche giorno fa abbiamo assistito ad un service-down da parte di Google, che ha precluso l’accesso ai dati personali e lavorativi di milioni di persone, le quali improvvisamente, non riuscivano più ad accedere all’account Gmail, ai dati (privati e di lavoro) su Google Drive etc…. (e la lista è lunga). Pensiamo ai danno provocati da questo “blackout informatico”. Tutto ciò non sarebbe accaduto se i dati a cui noi volevamo attingere fossero stati già salvati su IPFS perchè non dipendono dai servizi e dalle architetture di un’azienda, per grande che sia, ma sono attivi perchè condivisi e replicati da tutti i pc degli utenti che utilizzano questo sistema/protocollo. Quindi se io salvo in rete un documento, questo sarà accessibile fino a quando ci sarà anche solo 1 pc nella rete IPFS in grado di condividermelo. Seppur banalizzato, il concetto è questo ma, non tutto ciò che possiamo caricare su IPFS rimane in eterno, questo perchè non ci serve mantenere ogni cosa, quindi esiste un processo, il PINNING, che ci permette di dire alla rete quali file noi consideriamo IMPORTANTI e vogliamo vengano mantenuti, altrimenti IPFS ha un suo sistema di pulizia della cache per cui, tutto ciò che non è stato “pinnato” verrà svuotato. Un pò come il garbage collector.
PROBLEMA
Chiaramente nessun sistema è perfetto, dunque anche IPFS, seppur abbia ottimi punti di partenza e di futuro sviluppo, ha anch’esso alcuni aspetti problematici da tenere presente, ma così come la Blockchain ha creato i Bitcoin come sistema di INCENTIVAZIONE per poter far crescere l’uso della sua innovazione, così anche IPFS ha dovuto trovare la soluzione per lo stesso dilemma.
Infatti, il problema principale di IPFS è quello di riuscire a mantenere i file sempre disponibili, poichè se un file è condiviso da pochi nodi della rete questo diventerà non disponibile non appena questi nodi andranno offline, esattamente come capita su BitTorrent per i file con pochi seeders. L’unico modo per risolvere questo problema è offrire un incentivo ai nodi per rimanere online quanto più tempo possibile e distribuire così proattivamente i file sulla rete in modo che ci sia sempre un certo numero minimo garantito di nodi, che ne mantenga una copia disponibile.
SOLUZIONE
Per questo gli stessi sviluppatori di IPFS hanno creato il progetto Filecoin, una blockchain basata su IPFS che punta alla creazione di un mercato decentralizzato per lo storage di dati. In questo modo chi offre il proprio spazio di archiviazione per il salvataggio di dati su IPFS è al tempo stesso incentivato economicamente a farlo e a mantenere il proprio nodo online per quanto più tempo possibile. In pratica come Bitcoin per la Blockchain.
Di Filecoin parleremo approfonditamente in un prossimo articolo.
IPNS
L’IPNS, ossia Inter-Planetary Name System è la parte tecnologica di IPFS che possiamo associare a ciò che noi conosciamo sulla internet, basata sul protocollo HTTP, come il servizio DNS, tramite il quale possiamo navigare, grazie alla traduzione da indirizzo-IP basato su numeri, a sequenza ordinata di lettere che compongono gli URL che utilizziamo ogni giorno.
Secondo la documentazione ufficiale di IPFS:
” l’ IPNS è un sistema per la creazione e l’aggiornamento di collegamenti mutabili al contenuto IPFS. Poiché gli oggetti in IPFS sono indirizzati al contenuto, il loro indirizzo cambia ogni volta che il loro contenuto lo fa. È utile per una varietà di cose, ma rende difficile ottenere l’ultima versione di qualcosa.”
Quindi, un nome gestito su IPNS equivale all’hash di una chiave pubblica, ed è associato a un record contenente informazioni sull’hash a cui è collegato, che è firmato dalla chiave privata corrispondente. Chiaramente tutti i nuovi record possono essere firmati e pubblicati in qualsiasi momento.
OGNI COSA HA BISOGNO DEL PROPRIO ATTREZZO
Come ho carcato di spiegare (data la vastità dell’argomento) , IPFS può rendervi indipendenti dall’Internet tradizionale, infatti posso salvalre file, pubblicare un sito ed altro ancora, senza dover usare Google, un DNS, o avere un dominio comprato su un ISP……, già dimenticavo di dire che, così come oggi siamo abitutati a comprare e registrare un dominio per il nostro sito, la stessa cosa la possiamo fare in modo indipendente anche su IPFS, tramite ENS (Ethereum Name Service).
In questo caso possiamo vedere come due tecnologie, simili nei concetti, si possono unire, ed è il caso proprio di IPFS+ENS.
L’ Ethereum Name Service (ENS) è definito come un “sistema di denominazione distribuito, aperto ed estensibile basato sulla blockchain di Ethereum”. Ethereum, per coloro che non lo sapessero, è una piattaforma di contratto intelligente (una blockchain) che vanta un gran numero di applicazioni decentralizzate (dapps), una vivace community di sviluppatori e una dichiarata community di utenti.
ENS è stato progettato per creare un sistema simile al DNS, tuttavia, a causa della diversa architettura decentralizzata di Ethereum, l’ENS varia dalla struttura sfruttata nei sistemi DNS. Tuttavia, proprio come il DNS, l’ENS detiene un record di nomi gerarchici separati da punti chiamati domini, con il proprietario del dominio di primo livello che ha il pieno controllo sui sottodomini.
Ad esempio, se “tizio” possiede il dominio “soldiapalate.eth”, può creare “blog.soldiapalate.eth” e configurarlo come desidera.
Per gli utenti della rete principale di Ethereum, l’ENS semplifica decisamente le cose, inquanto migliora l’usabilità delle dapps restituendo, attraverso la risoluzione inversa, nomi leggibili dall’uomo invece dei lunghi hash di IPFS.
WEB 3.0
Come stavo chiarendo qui sopra, posso essere indipendente da tutto se voglio usare IPFS come sistema di backup/scambio di file ma, cosa succede se voglio usare queste nuove tecnologie per creare un sito web?. Da questi ragionamenti è nato quello che oggi è il web3, che accomuna sistemi decentralizzati come IPFS alle Blockchain, come Ethereum, ma non solo. Infatti, seppur abbiamo chiarito che IPFS funziona, a livello concettuale com Torrent, se i contenuti che voglio condividere sono presenti solo su un computer e quel computer, per qualsiasi motivo, non è disponibile, quei contenuti saranno irragingibili.
Per questo motivo, da qualche tempo per IPFS esistono anche dei servizi di pinning: che ci aiutano a garantire la disponibilità dei nostri contenuti. Tra questi, alcuni nomi sono quelli di Pinata, Infura ed anche il blasonato Cloudflare ha aggiunto tra i suoi servizi quelli di “Gateway Website for IPFS” …… and more.
Il vantaggio del Web 3.0 è che i dati sono distribuiti punto a punto, quindi non è necessario preoccuparsi di perdere i dati se i server sulla rete vengono interrotti. Non è lo stesso di un Web centralizzato, quando il server di accesso viene interrotto, non è possibile accedere al sito Web.
CONCLUSIONE
Per questo primo articolo introduttivo è tutto, nel prossimo inizieremo ad affrontare alcuni casi pratici per vedere come si salvano i dati, li si recuperino in caso di cancellazione, vedremo come attivare un nostro nodo locale e come accedere alla Dashboard di gestione del nodo, e come usare alcuni dei servizi di gateway per velocizzare e gestire il pinning dei dile importanti.
Siamo arrivati a quelle che già da molti mesi sono tra le elezioni presidenziali più attese degli ultimi anni, ed i mercati finanziari sono stati, come sempre, ricchi di chiacchiere, di ogni genere, colpi bassi, gossip di cattivo gusto, insomma di tutto quanto ormai abbiamo imparato essere il circo mediatico dietro ad uno degli eventi più importanti al mondo, per via delle ripercussioni, positive e negative, sulla maggior parte delle nazioni. Ma da qualche anno le implicazioni non sono più soltanto a carattere geo-politico e finanziario ma anche sui vari asset strategici della economia digitale, tra cui Bitcoin.
E’ ormai assodato che la relazione tra il “cripto mondo” e questo grande evento statunitense richieda ulteriori indagini, vista la sua rilevanza storica.
Infatti dobbiamo tenere presente che Bitcoin ha chiuso il mese di Ottobre, per la seconda volta, nella sua intera storia, intorno ai 14.000 dollari, l’unico precedente lo possiamo ritrovare soltanto in quel periodo tra la fine del 2017 e l’iniio del 2018, in cui arrivò addirittura a 20.000 dollari.
Del resto anche prima del rialzo del 2017, si erano svolte le elezioni americane del 2016 tra la Clinton e Trump. Dunque potrebbe significare che le elezioni statunitensi hanno un’ impatto su Bitcoin in un modo o nell’altro?
Volendo cercare una correlazione, andando indietro a verificare, potremmo notare che, nell’ultimo ciclo elettorale, Standard & Poor 500 (l’indice della borsa statunitense) aveva registrato volatilità durante il periodo delle elezioni. In particolare, durante il mese di Ottobre e la prima settimana di novembre 2016, l’SPX era calato di oltre il 6%, mentre subito dopo le elezioni, le azioni erano rapidamente risalite, invertendo la tendenza verso quelli che sarebbero diventati i nuovi massimi storici.
Quindi, da un lato, abbiamo una situazione in cui si potrebbe tracciare una correlazione causale tra l’andamento di Bitcoin e le elezioni presidenziali statunitensi, d’altro canto, si potrebbe anche sostenere che questa correlazione sia semplicemente il risultato dell’aver stampato e pompato nei mercati una grande quantità di denaro, la stessa FED aveva dichiarato qualche settimana fa che, a causa degli aiuti all’economia per via del Covid, nel solo 2020, sono stati stampati l’equivalente del 22% di tutti i dollari in circolazione.
Gli eventi che si sono abbattuti sull’economia, all’arrivo del 2020, hanno però modificato la visione di molte persone ed aziende, circa quello che Bitcoin può diventare, infatti, mentre prima era visto principalmente come un’ asset speculativo con una capitalizzazione di mercato di poco più di $ 200 miliardi, oggi si è guadagnato un nuovo ruolo, ossia quello di una moneta per salvaguardare le nostre richezze diventando noi, in primis, degli “holder”, pensando quindi principalmente ad un accumulo come forma di prossima ricchezza, contro la visione speculativa dell’inizio.
Non a caso, proprio in questo anno alcune Big, società quotate in borsa di grande reputazione, come Square e MicroStrategy (per citarne solo alcune), hanno portato l’argomento della “riserva di valore” ad un livello successivo, avendo collocato sul mercato digitale, una grossa percentuale delle loro riserve aziendali investendo diversi milioni di dollari nell’acquisto di Bitcoin.
L’ascesa di Bitcoin come riserva di valore
Tutto ciò di cui abbiamo discusso fino ad ora, ci porta dunque a trattare Bitcoin come la nuova “riserva di valore”. In effetti, in un periodo di accresciuta incertezza, la necessità di una riserva assoluta di valore è diventata ancora più una necessità.
Tradizionalmente, l’oro è il bene di rifugio verso cui gli investitori si affollano in tempi di crisi. Ma Bitcoin sembra essere diventato decisamente più interessante per gli investitori tecnologici di oggi, con scarso interesse per le proprietà ingombranti dell’oro.
Dall’inizio della crisi economica da Covid, lo stimolo di ricerca della “riserva di valore” su cui investire è cresciuta parecchio, volendo analizzare i due protagonisti del mercato possiamo notare che, l’oro è aumentato del 40% (dal minimo al massimo), mentre Bitcoin è aumentato di oltre il 120%. Questa discrepanza nelle prestazioni diventa ancora più chiara se vista in un arco di tempo di 10 anni.
Conclusione
In conclusione, avendo osservato che, nonostante gli avvicendamenti dei presidenti americani, da quando Bitcoin è nato, possiamo affermare con una certa sicurezza che le elezioni statunitensi alla fine avranno poca influenza sulla traiettoria di crescita a lungo termine di Bitcoin.
Quello che possiamo immaginare è che certamente, il giorno stesso delle elezioni, fino anche ad una settimana dopo, sarà ragionevole prevedere una reazione del mercato legacy al candidato vincitore, che potrebbe andare in entrambi i modi, poichè, in genere, i mercati preferiscono mantenere lo status quo, il che significherebbe la vittoria di Trump, che sarebbe percepita dai mercati come “business as usual”, mentre, il rovescio della medaglia avverrebbe, se Biden dovesse vincere, per cui, le percezioni dei mercati dipenderebbero dal discorso inaugurale dello stesso neo presidente.
Concludo, ribadendo che questa è un’analisi totalmente pesonale e, che quindi a mio parere, a prescindere da chi verrà eletto, Bitcoin procederà come sempre per la sua strada, nel caso della rielezione di Trump, senza eventuali battute di pausa, ma proseguendo il trend di crescita del 2020 per tutto il 2021, tornando a puntare verso quella quota 20.000 che aveva già raggiunto nel Dicembre 2017.